Connecting Data Stores
Unstructured Discovery helps you identify personal data hidden within unstructured content like files, documents, and emails. Before you can use this feature, you'll need to connect your unstructured data stores to Transcend. This guide explains how to make these connections.
To connect an unstructured data store for discovery:
-
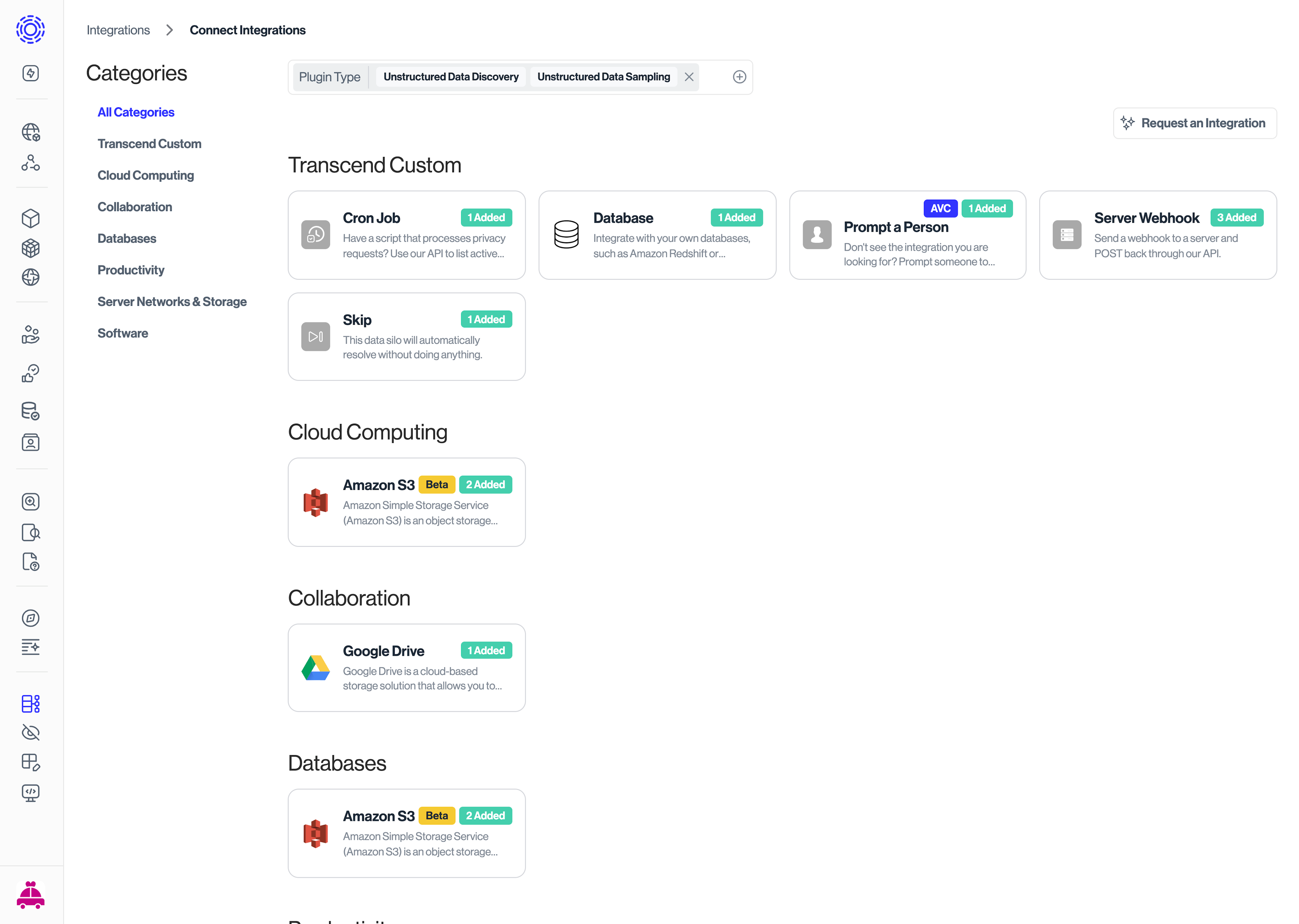
Navigate to Infrastructure > Integrations in the left sidebar
-
Click Add Integration
-
Search for and select your data store type (S3, Google Drive, Slack, etc.)
-
Follow the connection instructions, which typically involve:
- Authorizing via OAuth
- Entering API credentials
- Granting necessary permissions
-
Once connected, go to the Unstructured Discovery tab of the integration
-
Enable both the Unstructured Data Discovery and Unstructured Data Sampling plugins
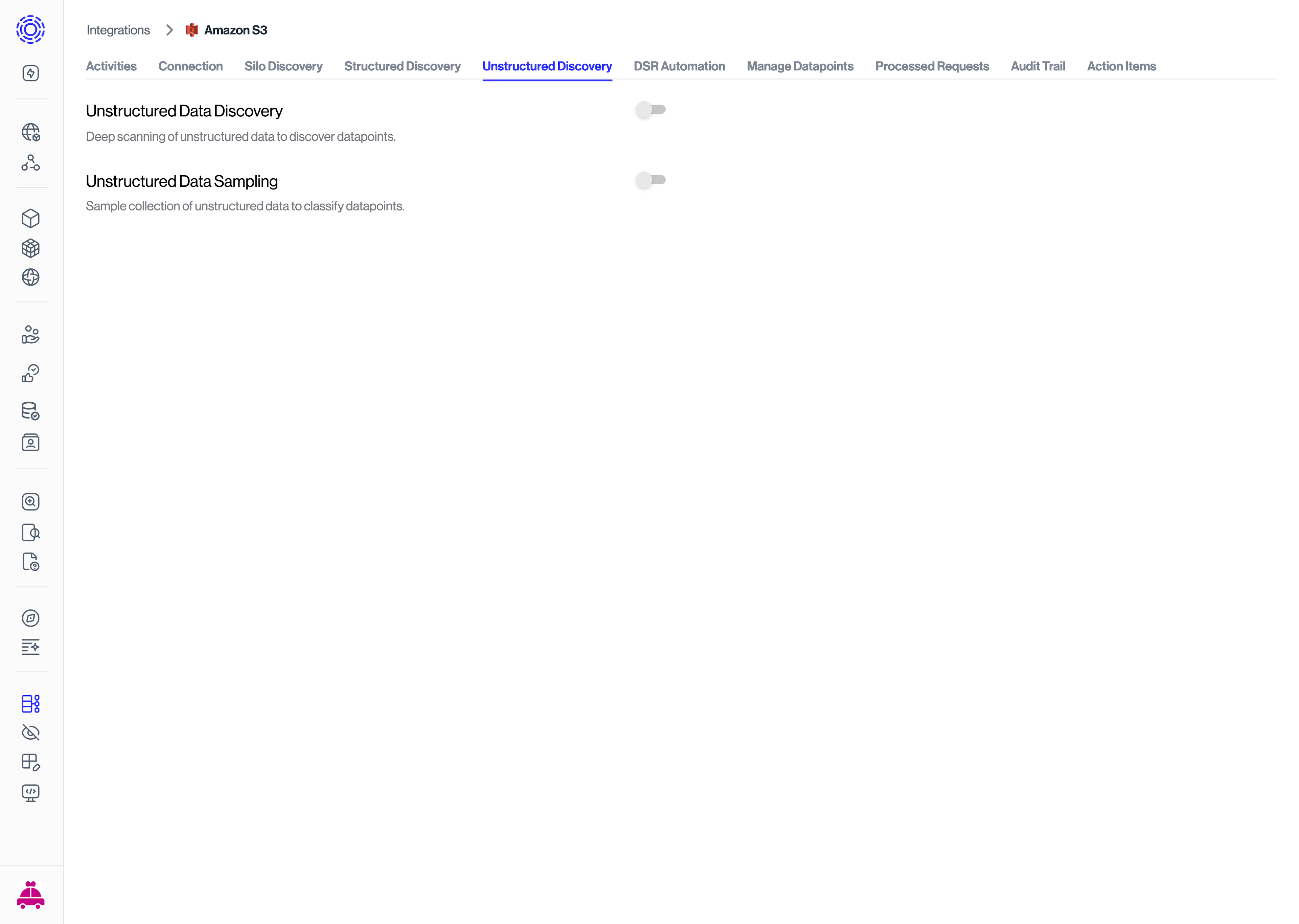
After enabling the plugins, Unstructured Discovery will begin scanning your data store, discovering files and analyzing their contents for personal data.
What is the potential cost of scanning, sampling, and classification?
The total cost depends on several factors:
- File System Access: Costs associated with accessing your file system
- Data Transfer: Costs for retrieving files during sampling
- Classification: If using self-hosted components, there are infrastructure costs for running the classifier service
- Sombra™ Hosting: If you're using self-hosted Sombra, there are associated hosting costs
For detailed information on hosting requirements, see our Hosted LLM Classifier documentation.
What file types are supported for sampling and classification?
Unstructured Discovery supports a wide range of file formats:
- Document files: PDF, TXT, DOCX
- Spreadsheets: CSV, XLSX, GSHEET
- Presentations: PPTX, GSLIDE
- Google Workspace: GDOC, GFORM
- Data files: JSON, BIN
- Archives: ZIP
Is it sampling all data?
Unstructured Discovery scans all files in your connected data store but has sampling limits to ensure efficient processing:
- General file limit: First 50MB of any file
- PDF specific limit: First 30MB of PDF files
These limits help balance comprehensive discovery with performance and cost considerations.