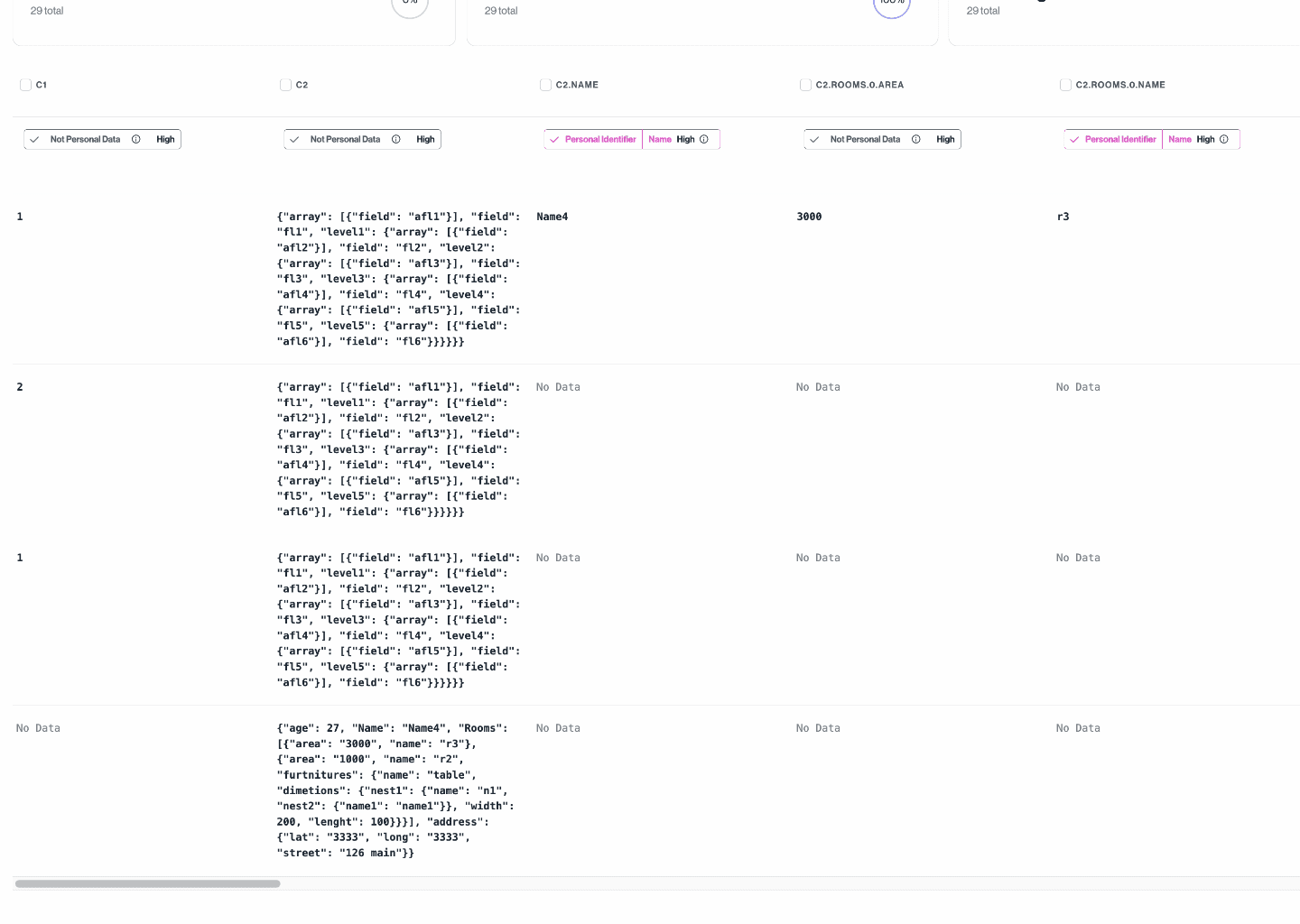
Classifying Semi-Structured Data
Many data systems store data as JSON blobs. Instead of classifying blobs of JSON, Transcend flattens (or "unnests") columns containing JSON
Any field containing data with a JSON structure will be expanded to generate new derived datapoint. The following steps are involved in the generation of derived datapoints:
- During discovery, we capture the data type of each datapoint.
- During the sampling process, if a datapoint's content is of type JSON, we flatten each sample into unique paths to fields that contain primitive types. Note: we only traverse the JSON structure up to 5 levels deep or until the path length is less than 100 characters.
- We merge paths and their associated values from all samples.
- Each unique path is now considered a derived datapoint and is independently classified to achieve more accurate predictions.
- These derived datapoints are shown as separate datapoints on the dashboard.
- When a parent datapoint is deleted, all of its derived datapoints are also deleted.
- When a derived datapoint is triggered for re-classification, we resample its parent datapoint and regenerate the derived datapoints based on the samples collected.
In the following picture, you can see expanded derived datapoints from c2 datapoint which is a column from a MySQL table containing JSON data.