Tabs in the Data Inventory
The Data Inventory brings together everything you need to document how personal data flows across your organization. Each tab surfaces a focused slice of information—systems, datapoints, classifications, and the business context that explains why the data exists. Working across the tabs gives you a complete, navigable map of your privacy footprint.
- data system – Inventory the data systems where personal data lives.
- datapoint – Explore all objects and properties captured across those systems.
- data category – Understand what types of personal data you maintain.
- purpose of processing – Document why data is collected and how it is used.
- vendor – Track the third parties that provide services and process your data.
- business entity – Organize data assets by internal brands, regions, or subsidiaries.
- processing activity – Map the business processes that rely on your data.
Use the tabs together: for example, opening a data system shows the datapoints it contains, while a data category quickly filters to the datapoints where that classification is applied.
Use the Data Systems tab to curate the authoritative list of systems that store or process personal data and stay aligned with what appears in Integrations.
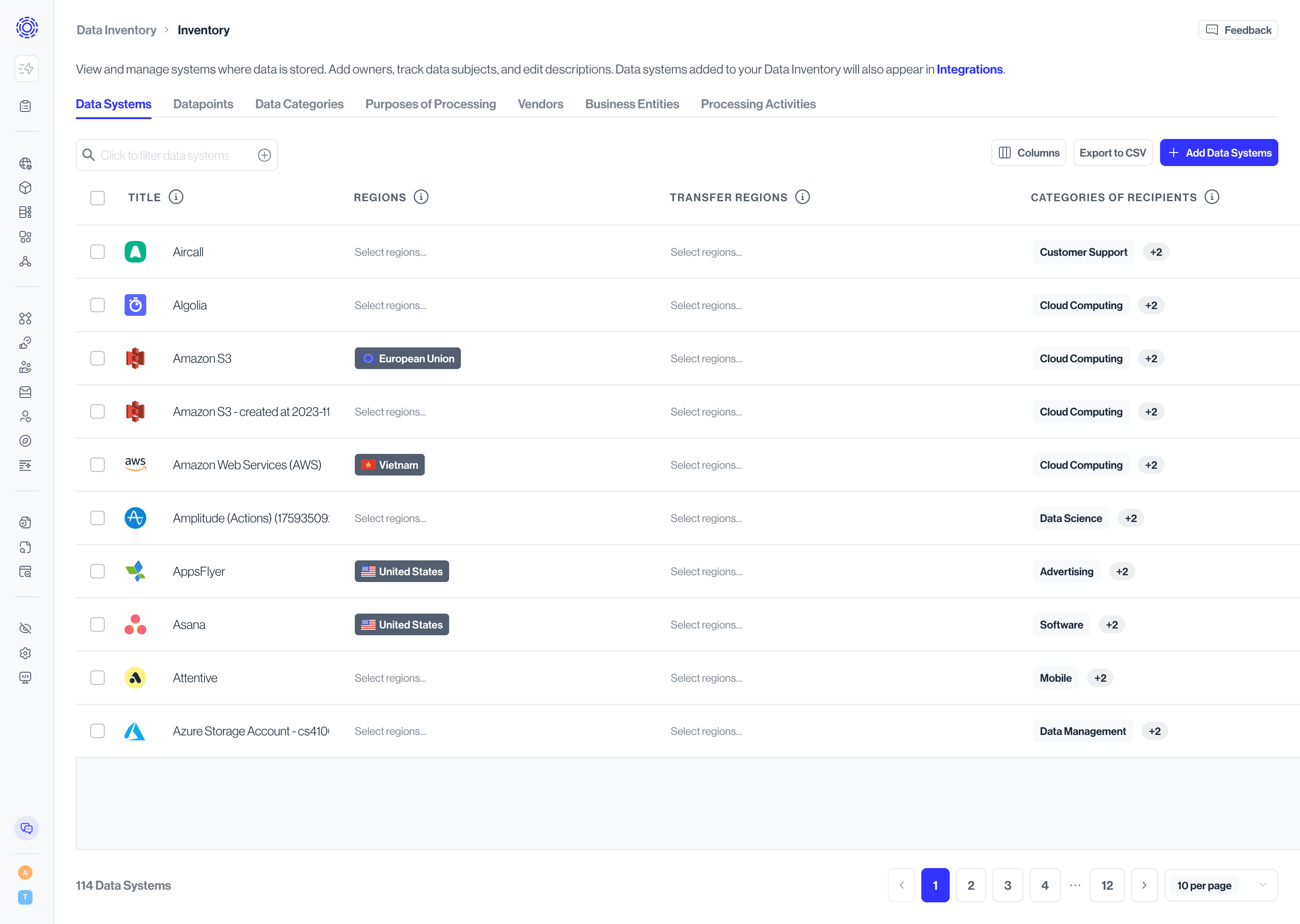
- Title – Displays the system name and logo. Systems added here appear across Transcend, including Integrations.
- Owner – Identifies the teammate accountable for the system. Update owners here to keep downstream workflows current.
- Datapoints – Shows how many datapoints are mapped to the system. Select the count to open those records in the Datapoints tab.
- Data Subjects – Highlights which groups of individuals have data in the system (for example, Customers or Employees).
- Data Categories & Purposes – Summaries of how the data in this system is classified and why it is processed.
- Description – Summarizes the system’s role; pre-populated for common tools but fully editable.
- Add Data System – Use this action to register new tools or databases as your data footprint evolves.
- Data Systems Found - Triage the systems you have discovered via System Discovery.
The Datapoints tab is the source of truth for every object, table, or field that contains personal data. Review the datapoints discovered across your structured systems, update classifications, and confirm whether a datapoint participates in a Data Subject Request (DSR) workflow.
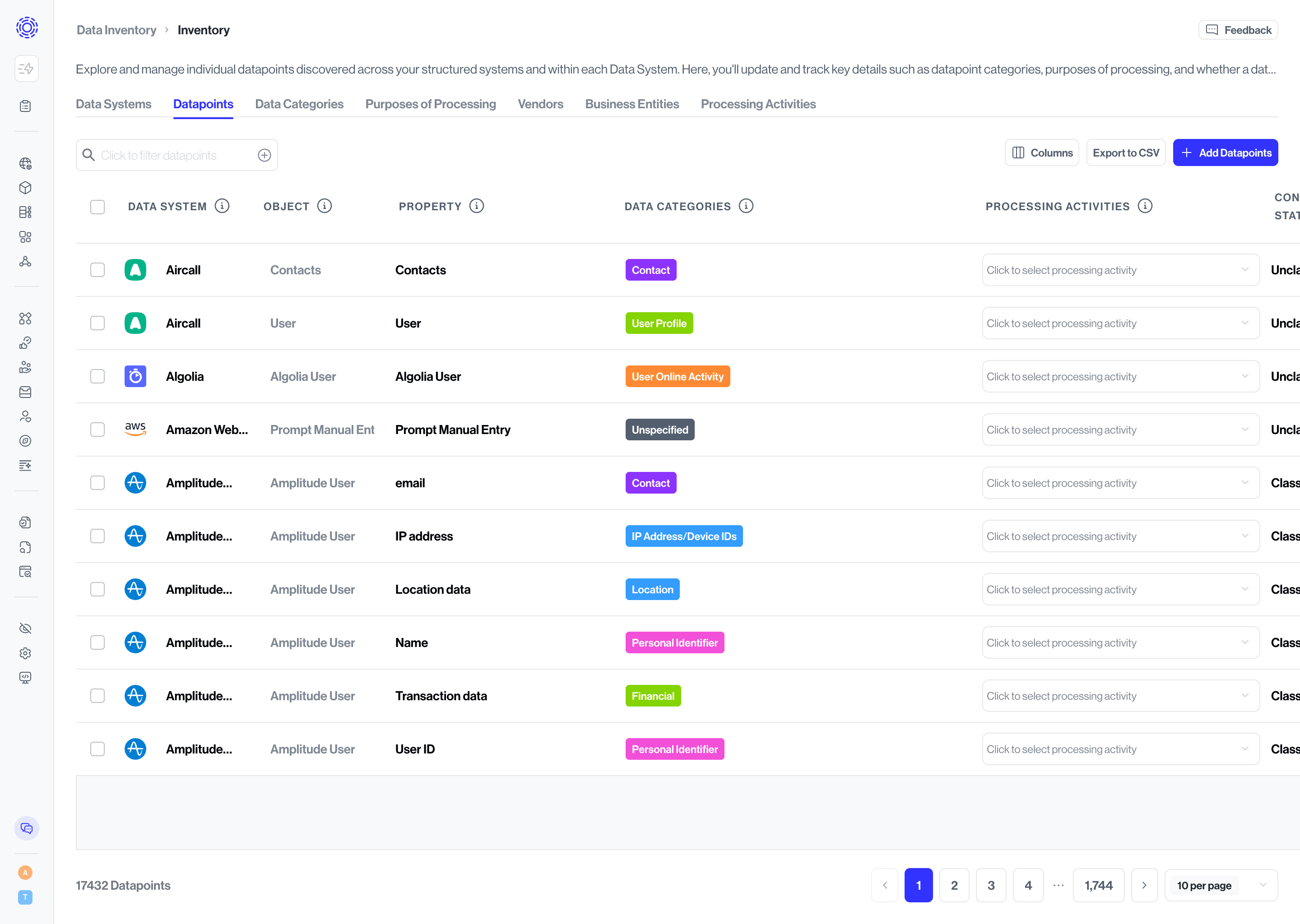
- Data System – The parent system where the datapoint or property resides.
- Vendor – The external organization that provides the system. Transcend’s catalog auto-suggests vendor metadata such as headquarters location and privacy policy.
- Business Entity – The internal brand, business unit, or subsidiary responsible for the data.
- Object / Property – The core data object (such as a database table) and its individual fields.
- Data Category – The classification describing what type of personal data is present (for example, Financial | Credit Card Number). Defaults are provided, and you can tailor them to your taxonomy.
- Purposes of Processing – Explains why the data is collected or used (for example, Marketing or Customer Support). Add or adjust purposes directly from this view as programs evolve.
- Description – Context on how the data is used, editable to reflect your specific implementation.
Adding classifications or purposes to individual properties in this tab rolls those values up to the parent datapoint record, the connected data system, and any associated vendors, business entities, and processing activities.
Accelerate discovery by running Classification scans, which automatically surface datapoints and suggested classifications for review.
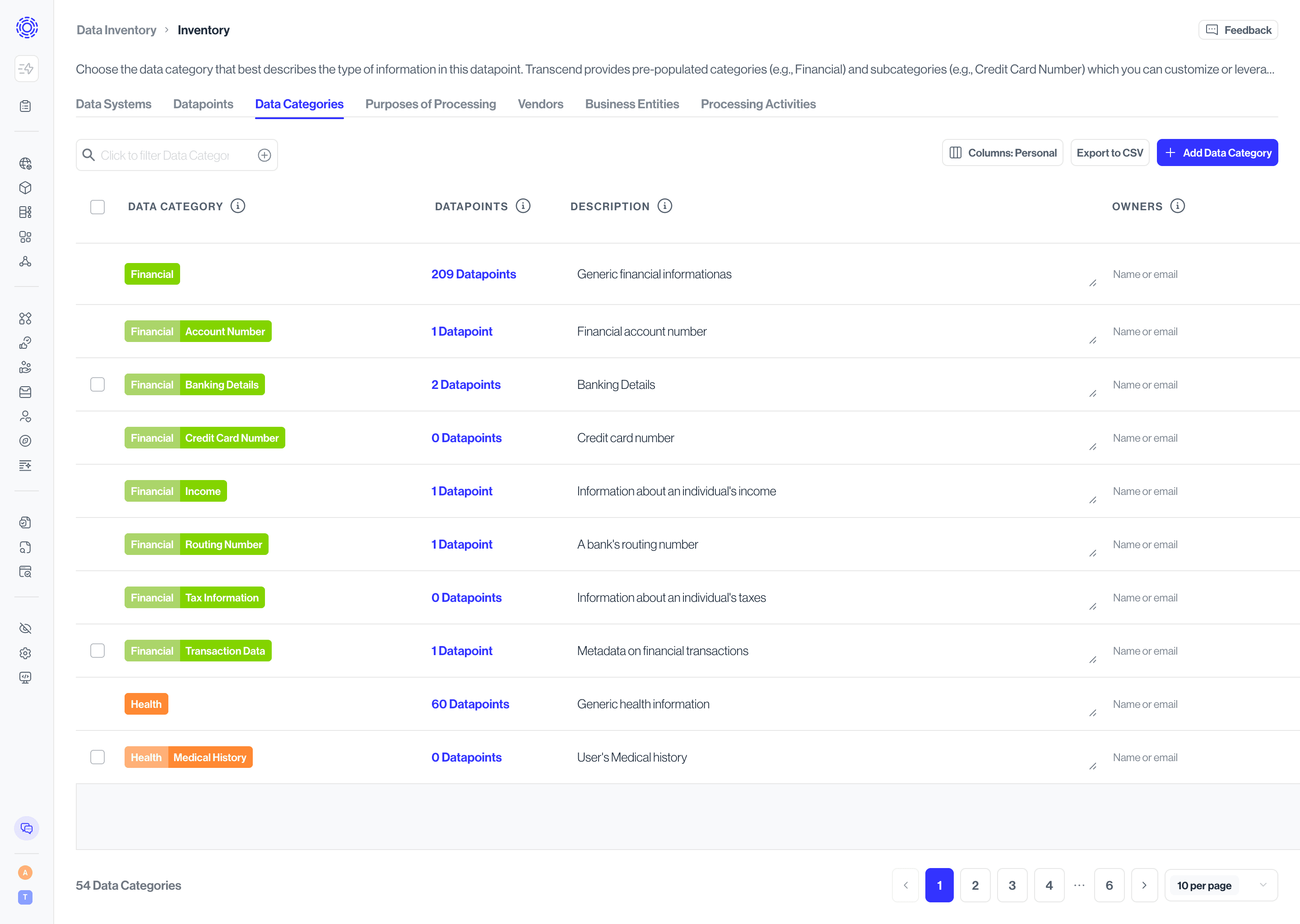
The Data Categories tab aggregates every category applied across your datapoints so you can confirm that sensitive or regulated data is properly managed. Transcend provides a library of categories (for example, Financial) and subcategories (for example, Credit Card Number) that you can customize. Selecting a category's datapoints drills into the datapoints that contain it, making it easy to review coverage or stakeholders for that type of data.
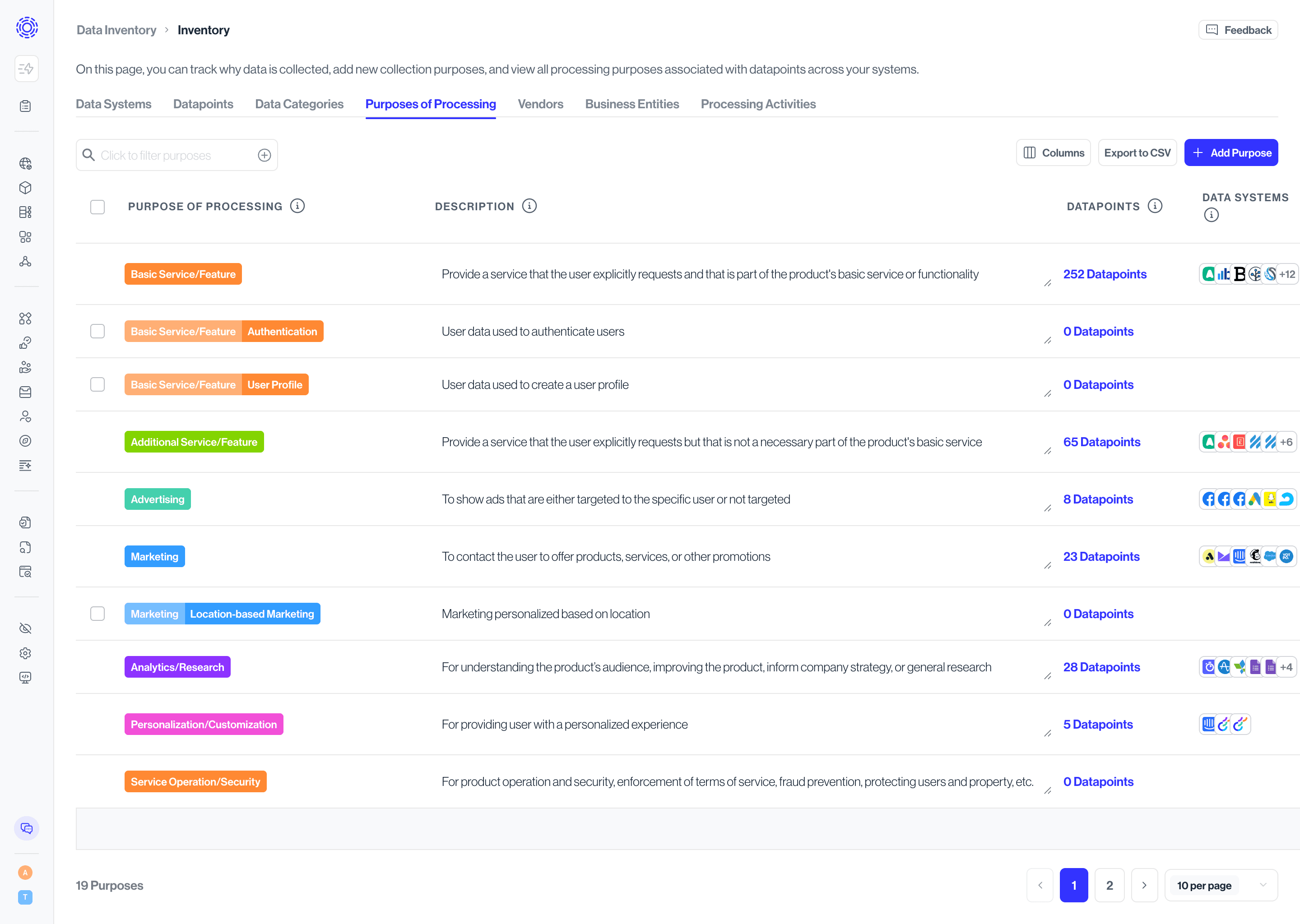
This view provides a similar rollup for processing purposes. Use it to confirm regulatory obligations (such as lawful basis), add new purposes as your programs expand, and review which datapoints support a given business objective. Clicking a purpose's datapoints filters the Datapoints tab to the relevant records.
The Vendors tab tracks the third parties and platforms that handle your personal data so you can maintain a comprehensive view of your processors. Each row represents a vendor, aggregating:
- Linked data systems and their datapoints.
- Suggested metadata from Transcend’s catalog, including headquarters location, description, and vendor privacy policy URL.
- Processing purposes and data categories connected to the vendor’s services.
Maintain this view to streamline vendor assessments and to keep contracts, privacy reviews, and data maps aligned.
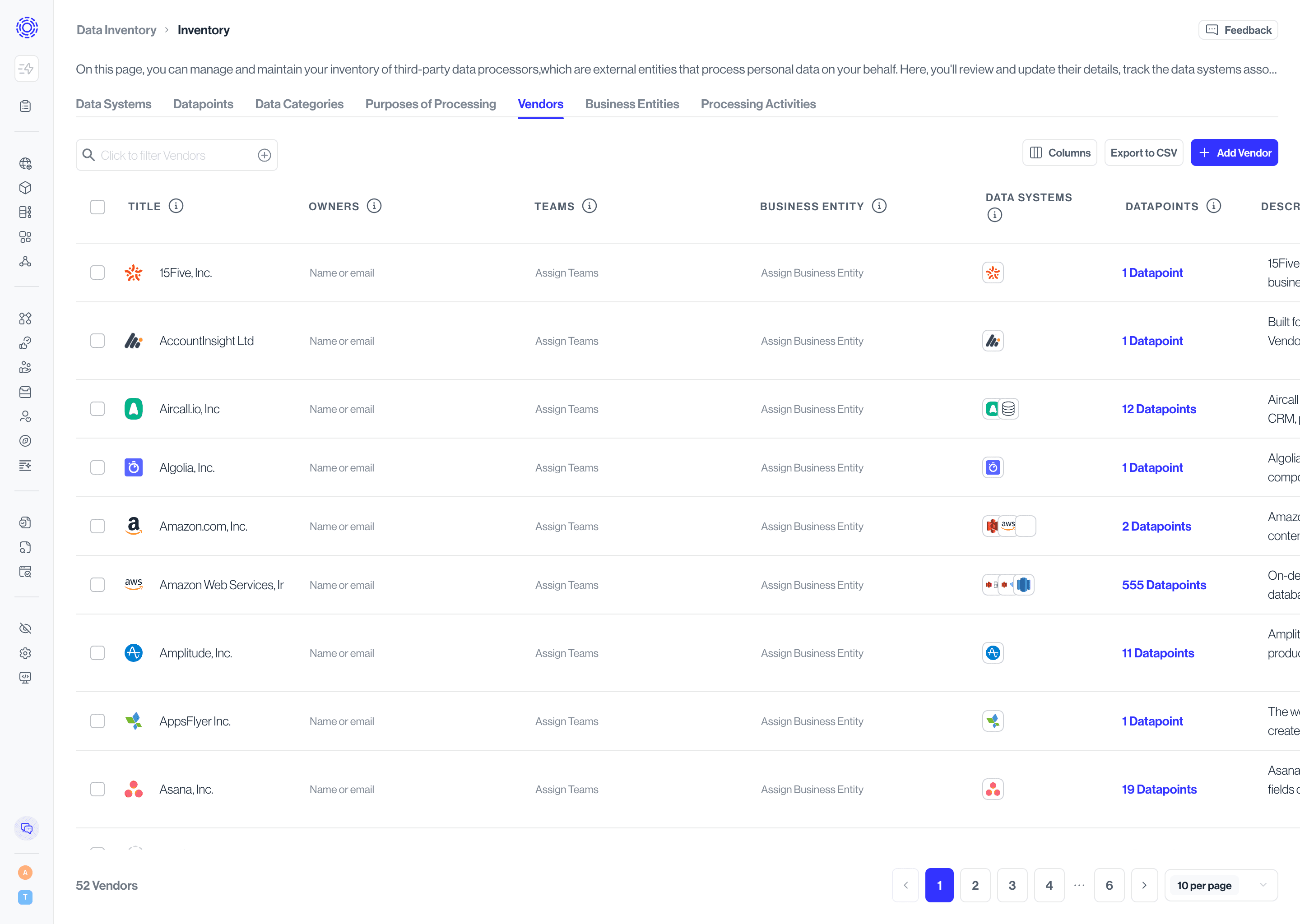
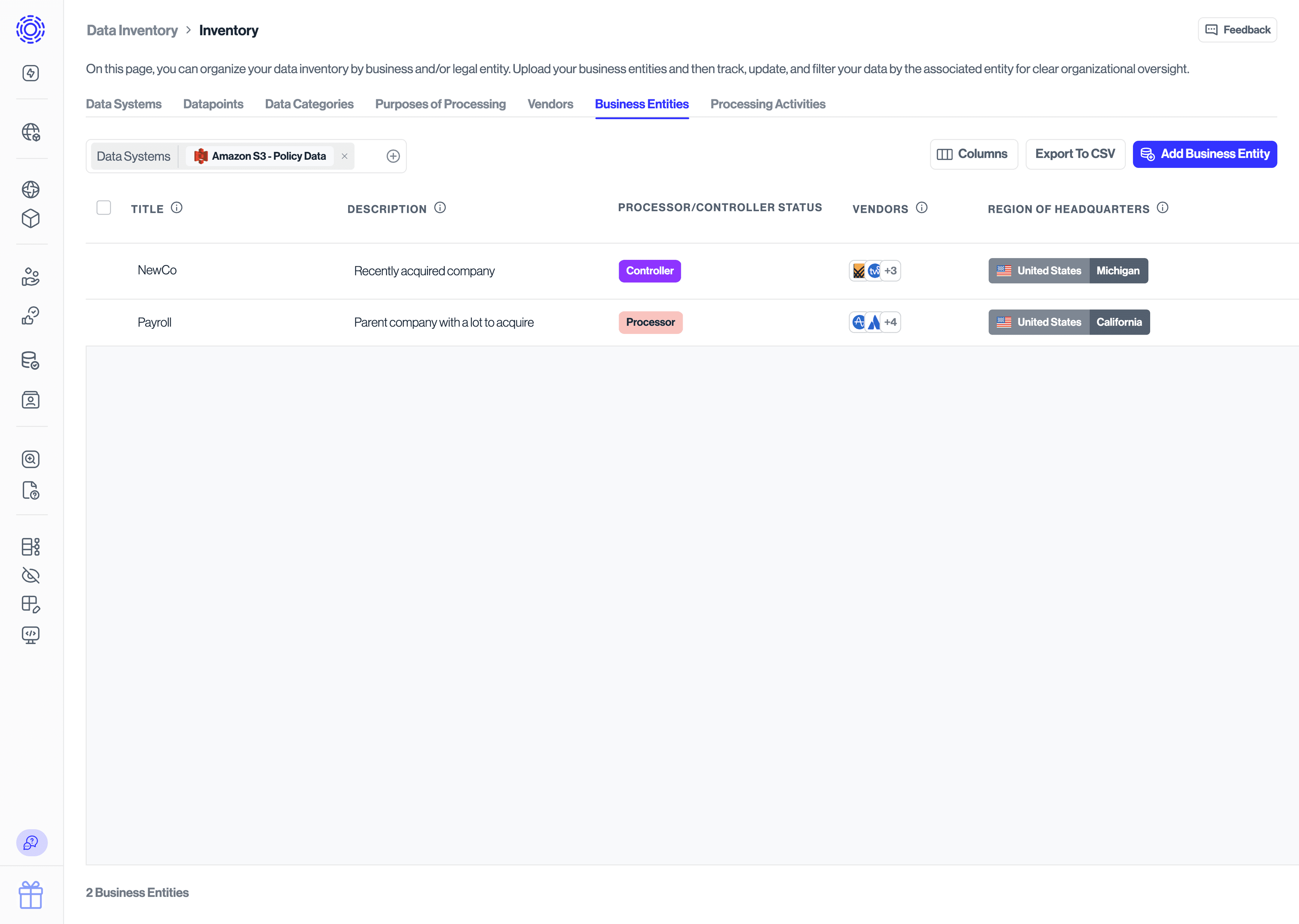
Use the Business Entities tab to slice your inventory by internal structure. Upload and manage business and legal entities, then associate data systems and datapoints with them so reporting, governance, and downstream obligations reflect how your organization actually operates. Filtering by a business entity in other tabs instantly narrows them to the relevant assets.
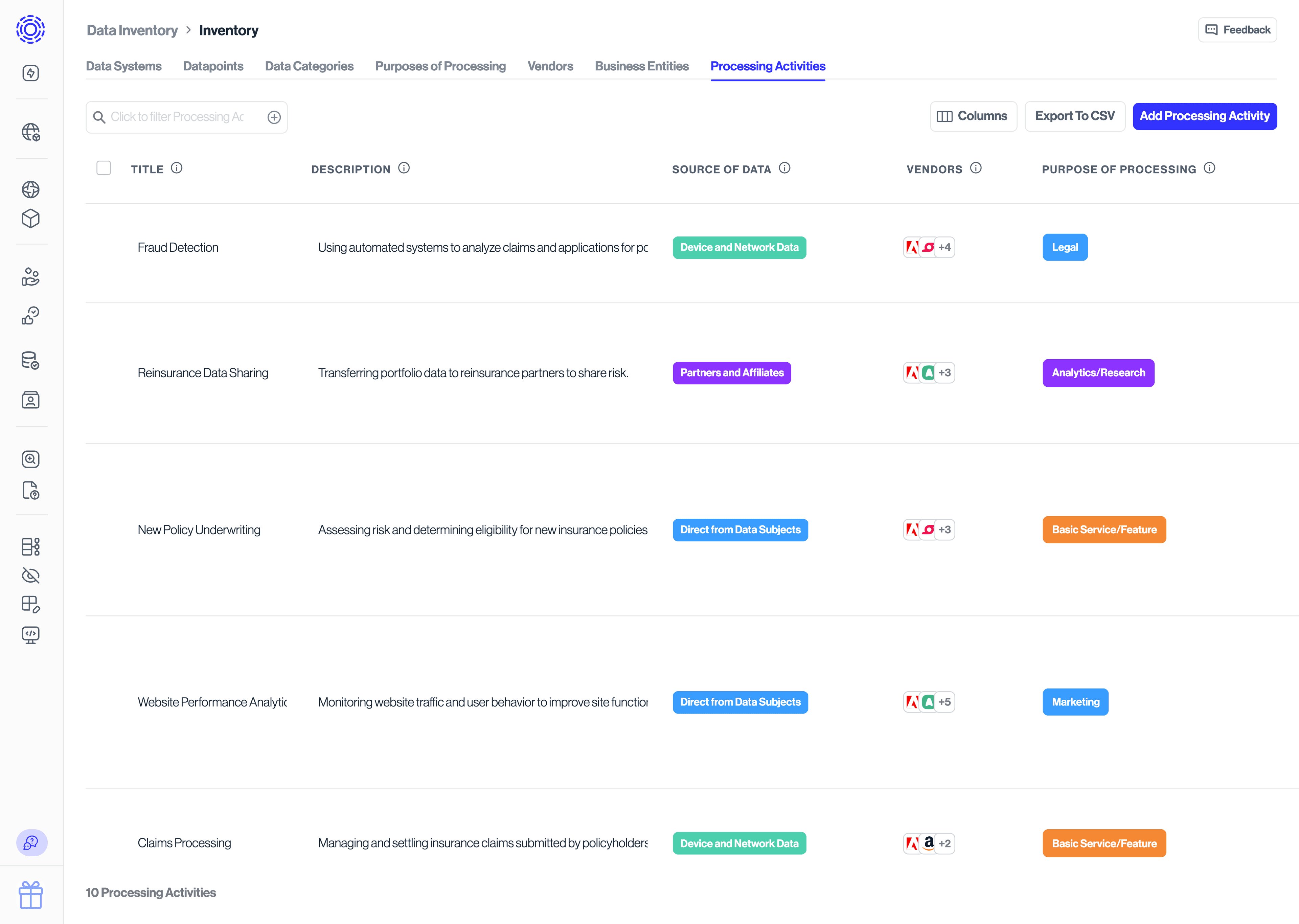
Processing Activities link the operational reasons you handle personal data to the systems, datapoints, categories, and purposes that support each activity. This tab helps you document regulatory requirements such as Records of Processing Activities (RoPA) and provides a single place to:
- Describe the business process (for example, Customer lifecycle marketing).
- Identify the lawful basis and retention considerations.
- Review which systems and datapoints participate in the activity.
- Confirm the data categories, purposes, and business entities implicated.
Keeping this tab up to date ensures you can explain the “why” behind any data asset during audits or privacy reviews.
Updates you make in one tab often surface on others. Use the table below to see how fields propagate across the inventory and where downstream views are read-only rollups.
| Asset | Inherited fields |
|---|---|
| Data systems |
|
| Data categories |
|
| Purposes of processing |
|
| Vendors |
|
| Business entities |
|
| Processing activities |
|
- Looking for event-level change history? The Audit Trail now lives under Data Asset Intelligence—see the Audit Trail guide for details.
- Need to manage person-level identifiers? Review the Identifiers overview.
- Configuring data subject types? Use the Data Subjects guide.