API to Write to Data Inventory
This guide runs through the API calls and developer tooling that can be used to push data into your Data Inventory from other sources.
Some useful resources to review before this guide:
- Check out this article to understand some potential motivations for using this API.
- Check out this article to understand the tabs and concepts in the Data Inventory like "Data Systems", "Vendors", "Data Categories", "Processing Purposes, "Identifiers", "Data Subjects" and more.
- Check out this tab to learn more about Developer Tools.
In general, there are 2 strategies for pushing data into the Data Inventory:
- Transcend CLI - This command line interface allows for you to generate an API key, pull configuration down from Transcend, modify that file locally, then push data back into Transcend. This avoids the need for you to implement pagination or understand the Transcend API shapes to push and pull data. This is the simplest way to push data.
- Transcend GraphQL API - Everything that you can do in the Transcend Admin Dashboard can also be done using this API. This allows for building highly specific queries and deeper to push data into Transcend. This is best for internal dashboards or higher-volume read & write activity.
Using the Transcend CLI is a great way to export your data from Transcend Data Inventory without needing to write code.
To start:
- Install the CLI using npm or yarn.
- Generate an API key in the Transcend Dashboard. You will need to assing the API key scopes. These scopes will vary depending on which resource types you intend to push and pull.
- Run the CLI command in your terminal to export your Data Inventory to a yml file.
You can see all examples of usage here as well as some example transcend.yml files here.
Some common example:
If you have multiple Transcend instances (e.g. a Production instance and a Sandbox instance), you can use the CLI to sync configuration between two accounts. You will need to generate an API for the source account to pull from TRANSCEND_API_KEY_SOURCE and an API key for the destination account TRANSCEND_API_KEY_DESTINATION
transcend inventory pull --auth=$TRANSCEND_API_KEY_SOURCE --resources=dataSilos,vendors,identifiers --file=./transcend.yml
transcend inventory push --auth=$TRANSCEND_API_KEY_DESTINATION --file=./transcend.ymlWhatever resources are defined in the Transcend file are pushed up on the transcend inventory push command. If necessary, you can modify the transcend.yml file manually or programmaticaly in between pulling and pushing the configuration across instance. The CLI is designed to generally only upsert data based on unique, human readable identifiers which makes it great for syncing data between accounts in a safe manner.
Some resource types have extra arguments that can be explored here. Some examples include:
Auto-classify the Data Flow service if not specified:
transcend inventory pull --auth=$TRANSCEND_API_KEY_SOURCE --resources=dataFlows
transcend inventory push --auth=$TRANSCEND_API_KEY_DESTINATION --resources=dataFlows --classifyService=trueCustom Fields (also know as attributes in our APIS), have an extra flag to delete any attribute values not specified rather than defaulting to only adding new values to the existing customer field.
transcend inventory pull --auth=$TRANSCEND_API_KEY_SOURCE --resources=attributes
transcend inventory push --auth=$TRANSCEND_API_KEY_DESTINATION --resources=attributes --deleteExtraAttributeValues=trueIn some situations, you may wish to define parts of your Transcend configuration in code. You can view a variety of examples in the CLI GitHub repository.
One common example of this would be if you wanted to define some Data Systems metadata, with their respective DSR Automation configuration in the codebase:
# yaml-language-server: $schema=https://raw.githubusercontent.com/transcend-io/tools/refs/heads/main/packages/cli/schema/transcend-yml-schema-latest.json
# Manage at: https://app.transcend.io/infrastructure/api-keys
# See https://docs.transcend.io/docs/authentication
# Define API keys that may be shared across data systems
# in the data map. When creating new data systems through the yaml
# cli, it is possible to specify which API key should be associated
# with the newly created data system.
api-keys:
- title: Webhook Key
- title: Analytics Key
# Manage at: https://app.transcend.io/privacy-requests/email-templates
# See https://docs.transcend.io/docs/privacy-requests/configuring-requests/email-templates
# Define email templates here.
templates:
- title: Your Data Report is Ready
- title: We Love Data Rights And You Do Too
# Manage at: https://app.transcend.io/privacy-requests/identifiers
# See https://docs.transcend.io/docs/identity-enrichment
# Define enricher or pre-flight check webhooks that will be executed
# prior to privacy request workflows. Some examples may include:
# - identity enrichment: look up additional identifiers for that user.
# i.e. map an email address to a user ID
# - fraud check: auto-cancel requests if the user is flagged for fraudulent behavior
# - customer check: auto-cancel request for some custom business criteria
enrichers:
- title: Basic Identity Enrichment
description: Enrich an email address to the userId and phone number
url: https://example.acme.com/transcend-enrichment-webhook
input-identifier: email
output-identifiers:
- userId
- phone
- myUniqueIdentifier
- title: Fraud Check
description: Ensure the email address is not marked as fraudulent
url: https://example.acme.com/transcend-fraud-check
input-identifier: email
output-identifiers:
- email
# Only call the webhook on certain action types
privacy-actions:
- ERASURE
# Note: description is an optional field
- title: Analytics Enrichment
url: https://analytics.acme.com/transcend-enrichment-webhook
input-identifier: userId
output-identifiers:
- advertisingId
# Manage at: https://app.transcend.io/privacy-requests/connected-services
# See https://docs.transcend.io/docs/the-data-map#data-silos
# Define the data systems in your data map. A data system can be a database,
# or a web service that may use a collection of different data systems under the hood.
data-silos:
# Note: title is the only required top-level field for a data system
- title: Redshift Data Warehouse
description: The mega-warehouse that contains a copy over all SQL backed databases
# The webhook URL to notify for data privacy requests
url: https://example.acme.com/transcend-webhook
headers:
- name: test
value: value
isSecret: true
- name: dummy
value: dummy
isSecret: false
integrationName: server
# The title of the API key that will be used to respond to privacy requests
api-key-title: Webhook Key
# Specify which data subjects may have personally-identifiable-information (PII) within this system
# This field can be omitted, and the default assumption will be that the system may potentially
# contain PII for any potential data subject type.
data-subjects:
- customer
- employee
- newsletter-subscriber
- b2b-contact
# When this data system implements a privacy request, these are the identifiers
# that should be looked up within this system.
identity-keys:
- email
- userId
# When a data erasure request is being performed, this data system should not be deleted from
# until all of the following data systems were deleted first. This list can contain other internal
# systems defined in this file, as well as any of the SaaS tools connected in your Transcend instance.
deletion-dependencies:
- Identity Service
# The email addresses of the employees within your company that are the go-to individuals
# for managing this data system
owners:
- alice@transcend.io
teams:
- Developer
- Request Management
# Datapoints are the different types of data models that existing within your data system.
# If the data system is a database, these would be your tables.
# Note: These are currently called "datapoints" in the Transcend UI and documentation.
# See: https://docs.transcend.io/docs/the-data-map#datapoints
datapoints:
- title: Webhook Notification
key: _global
# The types of privacy actions that this webhook can implement
# See "RequestActionObjectResolver": https://github.com/transcend-io/privacy-types/blob/main/src/actions.ts
# AUTOMATED_DECISION_MAKING_OPT_OUT: Opt out of automated decision making
# CONTACT_OPT_OUT: Opt out of all communication
# SALE_OPT_OUT: Opt-out of the sale of personal data
# TRACKING_OPT_OUT: Opt out of tracking
# ACCESS: Data Download request
# ERASURE: Erase the profile from the system
# ACCOUNT_DELETION: Run an account deletion instead of a fully compliant deletion
# RECTIFICATION: Make an update to an inaccurate record
# RESTRICTION: Restrict processing
privacy-actions:
- ACCESS
- ERASURE
- SALE_OPT_OUT
- title: User Model
description: The centralized user model user
# AKA table name
key: users
owners:
- test@transcend.io
teams:
- Platform
- Customer Experience
# The types of privacy actions that this datapoint can implement
# See "InternalDataSiloObjectResolver": https://github.com/transcend-io/privacy-types/blob/main/src/actions.ts
# ACCESS: Data Download request
privacy-actions:
- ACCESS
# Provide field-level metadata for this datapoint.
fields:
- key: firstName
title: First Name
description: The first name of the user, inputted during onboarding
# The category of personal data for this datapoint
# See: https://github.com/transcend-io/privacy-types/blob/main/src/objects.ts
# FINANCIAL: Financial information
# HEALTH: Health information
# CONTACT: Contact information
# LOCATION: Geo-location information
# DEMOGRAPHIC: Demographic Information
# ID: Identifiers that uniquely identify a person
# ONLINE_ACTIVITY: The user's online activities on the first party website/app or other websites/apps
# USER_PROFILE: The user’s profile on the first-party website/app and its contents
# SOCIAL_MEDIA: User profile and data from a social media website/app or other third party service
# CONNECTION: Connection information for the current browsing session, e.g. device IDs, MAC addresses, IP addresses, etc.
# TRACKING: Cookies and tracking elements
# DEVICE: Computer or device information
# SURVEY: Any data that is collected through surveys
# OTHER: A specific type of information not covered by the above categories
# UNSPECIFIED: The type of information is not explicitly stated or unclear
categories:
- category: USER_PROFILE
name: Name
# What is the purpose of processing for this datapoint/table?
# See: https://github.com/transcend-io/privacy-types/blob/main/src/objects.ts
# ESSENTIAL: Provide a service that the user explicitly requests and that is part of the product's basic service or functionality
# ADDITIONAL_FUNCTIONALITY: Provide a service that the user explicitly requests but that is not a necessary part of the product's basic service
# ADVERTISING: To show ads that are either targeted to the specific user or not targeted
# MARKETING: To contact the user to offer products, services, or other promotions
# ANALYTICS: For understanding the product’s audience, improving the product, inform company strategy, or general research
# PERSONALIZATION: For providing user with a personalized experience
# OPERATION_SECURITY: For product operation and security, enforcement of terms of service, fraud prevention, protecting users and property, etc.
# LEGAL: For compliance with legal obligations
# TRANSFER: For data that was transferred as part of a change in circumstance (e.g. a merger or acquisition)
# SALE: For selling the data to third parties
# HR: For personnel training, recruitment, payroll, management, etc.
# OTHER: Other specific purpose not covered above
# UNSPECIFIED: The purpose is not explicitly stated or is unclear
purposes:
- purpose: PERSONALIZATION
name: Other
- key: email
title: Email
description: The email address of the user
categories:
- category: CONTACT
name: Email
- category: USER_PROFILE
name: Name
purposes:
- purpose: ESSENTIAL
name: Login
- purpose: OPERATION_SECURITY
name: Other
- title: Demo Request
key: demos
description: A demo request by someone that does not have a formal account
privacy-actions:
- ACCESS
fields:
- key: companyName
title: Company Name
description: The name of the company of the person requesting the demo
categories:
- category: CONTACT
name: Other
purposes:
- purpose: ESSENTIAL
name: Demo
- key: email
title: Email
description: The email address to use for coordinating the demo
categories:
- category: CONTACT
name: Email
purposes:
- purpose: ESSENTIAL
name: Demo
- title: Password
key: passwords
description: A password for a user
fields:
- key: hash
title: Password Hash
description: Hash of the password
categories:
- category: OTHER
name: Password
purposes:
- purpose: OPERATION_SECURITY
name: Other
- key: email
title: Email
description: The email address to use for coordinating the demo
categories:
- category: CONTACT
name: Email
purposes:
- purpose: OPERATION_SECURITY
name: Other
# Defined web services in addition or instead of databases.
# The examples below define a subset of the fields.
# The remainder of the fields will be managed through the Transcend admin dashboard
# at the link: https://app.transcend.io/privacy-requests/connected-services
- title: Identity Service
description: Micro-service that stores user metadata
integrationName: server
# Share the API key between services
api-key-title: Webhook Key
teams:
- Developer
datapoints:
- title: Webhook Notification
key: _global
privacy-actions:
- ACCESS
- CONTACT_OPT_OUT
- title: Auth User
description: The centralized authentication object for a user
key: auth
privacy-actions:
- ACCESS
- title: Analytics Service
integrationName: server
data-subjects:
- customer
# The title of the API key that will be used to respond to privacy requests
api-key-title: Analytics Key
# Specify this flag if the data system is under development and should not be included
# in production privacy request workflows. Will still sync metadata to app.transcend.io.
disabled: trueSince the CLI is able to do an upsert, you would define only the configuration that you care to control in your codebase in this file, and you can leave all other fields blank that you wish to manage in the Admin Dashboard.
You can then setup a CI job that would run sync this file into your Transcend instance after changes go through code review and merge to your base development branch.
Below is an example of how to set this up using a GitHub action:
name: Transcend Data Map Syncing
# See https://app.transcend.io/privacy-requests/connected-services
on:
push:
branches:
- 'main'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v2
with:
node-version: '16'
- name: Install Transcend cli
run: npm i -D @transcend-io/cli
# If you have a script that generates your transcend.yml file from
# an ORM or infrastructure configuration, add that step here
# Leave this step commented out if you want to manage your transcend.yml manually
# - name: Generate transcend.yml
# run: ./scripts/generate_transcend_yml.py
- name: Push Transcend config
run: npx transcend inventory push --auth=${{ secrets.TRANSCEND_API_KEY }}If you want to sync the same configuration into multiple Transcend instances, you may find the need to make minor modifications to your configurations between environments. The most notable difference would be the domain where your webhook URLs are hosted on which may vary between staging and production.
The transcend inventory push command takes in a parameter variables. This is a CSV of key:value pairs.
transcend inventory push --auth=$TRANSCEND_API_KEY --variables=domain:acme.com,stage:stagingThis command could would insert the variables into your YAML file wherever you use the <<parameters.param_name>> syntax.
api-keys:
- title: Webhook Key
enrichers:
- title: Basic Identity Enrichment
description: Enrich an email address to the userId and phone number
# The data system webhook URL is the same in each environment,
# except for the base domain in the webhook URL.
url: https://example.<<parameters.domain>>/transcend-enrichment-webhook
input-identifier: email
output-identifiers:
- userId
- phone
- myUniqueIdentifier
- title: Fraud Check
description: Ensure the email address is not marked as fraudulent
url: https://example.<<parameters.domain>>/transcend-fraud-check
input-identifier: email
output-identifiers: - email
privacy-actions: - ERASURE
data-silos:
- title: Redshift Data Warehouse
integrationName: server
description: The mega-warehouse that contains a copy over all SQL backed databases - <<parameters.stage>>
url: https://example.<<parameters.domain>>/transcend-webhook
api-key-title: Webhook KeyOftentimes, your development team may define database definitions in code, often in application-specific tools called Database ORMs. Some common JavaScript examples include Sequelize and Prisma, other Python examples include SQL Alchemy and Alembic. You may even have your own general abstraction layer over your database definitions such that you have the ability to read in metadata about your database in your application code.
To achieve this, you will likely need to write a custom script that can extract the necessary information from you codebase. Below are some examples in JavaScript, however you can likely copy these scripts into ChatGPT and provide further promting to create a script that is custom to your use case and in the language of your choice.
A simple example of this in JavaScript may look like:
import { readFileSync, writeFileSync } from 'fs';
import yaml from 'js-yaml';
import { join } from 'path';
import type { TranscendInput } from '@transcend-io/cli';
import { MAIN_ROOT } from '@main/node-utils';
import { MODELS } from './models';
/**
* Read in the contents of a yaml file and validate that the shape
* of the yaml file matches the codec API
*
* This function can also be imported from `@transcend-io/cli` with extra runtime type validation.
*
* @param filePath - Path to yaml file
* @returns The contents of the yaml file, type-checked
*/
function readTranscendYaml(filePath: string): TranscendInput {
// Read in contents
const fileContents = readFileSync(filePath, 'utf-8');
// Validate shape
return yaml.load(fileContents);
}
/**
* Write a Transcend configuration to disk
*
* This function can also be imported from `@transcend-io/cli` with extra runtime type validation.
*
* @param filePath - Path to yaml file
* @param input - The input to write out
*/
function writeTranscendYaml(filePath: string, input: TranscendInput): void {
writeFileSync(filePath, yaml.dump(input));
}
/**
* This function generates our `transcend.yml` that is then synced into the Transcend Data Inventory
*
* @see https://app.transcend.io/data-map/data-inventory/data-silos
*
* The function extracts metadata about our database tables and columns, reads in the transcend.yml file
* then writes the updated metadata back to the transcend.yml.
*
* This file is then pushed up using the `transcend inventory push` command
* @see https://github.com/transcend-io/tools/blob/main/packages/cli/README.md#transcend-inventory-push
*/
async function generateTranscendYml() {
const transcendYml = join(MAIN_ROOT, 'transcend.yml');
// Generate trancsend.yml
const transcendYmlDefinition = readTranscendYaml(transcendYml);
const dataSilos = transcendYmlDefinition['data-silos'] || [];
const titles = dataSilos.map(({ title }) => title);
const postgresDbIndex = titles.indexOf('Postgres RDS Database');
if (postgresDbIndex < 0) {
throw new Error(`Failed to find database definitions in transcend.yml`);
}
const postgres = dataSilos[postgresDbIndex];
postgres.disabled = true;
postgres.datapoints = Object.entries(MODELS).map(([modelName, model]) => ({
title: modelName,
key: model.key,
description: model.comment,
fields: Object.entries(model.schema).map(([fieldName, field]) => ({
key: fieldName,
title: field.displayName,
})),
}));
console.success(`Found ${postgres.datapoints.length} datapoints in Postgres`);
// Write out transcend.yml file
writeTranscendYaml(transcendYml, transcendYmlDefinition);
}
generateTranscendYml();A more complex example may involve regular express parsing on the contents of a file, using external libraries like doctrine to parse documentation formats, or mapping multiple databases into your transcend.yml file.
An example of this includes:
import doctrine from 'doctrine';
import type { Schema } from 'dynamoose/dist/Schema';
import { existsSync, readFileSync, writeFileSync } from 'fs';
import glob from 'glob';
import yaml from 'js-yaml';
import difference from 'lodash/difference';
import { join } from 'path';
import type { TranscendInput } from '@transcend-io/cli';
import { DYNAMO_MODEL_DEFINITIONS, MIGRATION_MODEL_MAP, MAIN_ROOT, SEEDERS_MODEL_MAP } from './models';
import { MIGRATION_MODEL_MAP } from '@main/migration-helpers';
import { MAIN_ROOT, readFile } from '@main/node-utils';
import { SEEDERS_MODEL_MAP } from '@main/seeders';
const POSTGRES_DATABASE_MODELS = {
...SEEDERS_MODEL_MAP,
...MIGRATION_MODEL_MAP,
};
const GET_CLASS_COMMENT = /(\/\*\*[\s\S]*\*\/)\nexport class/;
/**
* Index of database metadata
*/
type IndexedDatabaseModels = {
[modelName in string]: {
/** Name of package where model lives */
packageName: string;
/** Path to definition file */
definitionFilePath: string;
/** Path to model definition */
modelFilePath: string;
/** Database table description */
description: string;
/** Dynamo model definition */
dynamoModel?: unknown;
/** Postgres model definition */
postgresModel?: unknown;
};
};
/**
* Read in the contents of a yaml file and validate that the shape
* of the yaml file matches the codec API
*
* This function can also be imported from `@transcend-io/cli` with extra runtime type validation.
*
* @param filePath - Path to yaml file
* @returns The contents of the yaml file, type-checked
*/
function readTranscendYaml(filePath: string): TranscendInput {
// Read in contents
const fileContents = readFileSync(filePath, 'utf-8');
// Validate shape
return yaml.load(fileContents);
}
/**
* Write a Transcend configuration to disk
*
* This function can also be imported from `@transcend-io/cli` with extra runtime type validation.
*
* @param filePath - Path to yaml file
* @param input - The input to write out
*/
function writeTranscendYaml(filePath: string, input: TranscendInput): void {
writeFileSync(filePath, yaml.dump(input));
}
/**
* Index all database models found in the codebase
* Assumes that each database definition is defined in a file
* named definition.ts and file named <ModelName>.ts
* Postgres models using wildebeest should also have a Base.ts file
*
* @returns The map of model name to metadata about that model
*/
function indexDatabaseModels(): IndexedDatabaseModels {
// Find all database model definitions
const definitionFiles = glob.sync(
`${MAIN_ROOT}/backend-support/**/definition.ts`,
);
return definitionFiles.reduce((acc, fileName) => {
const splitFile = fileName.split('/');
const srcIndex = splitFile.indexOf('src');
if (srcIndex < 1) {
throw new Error(`Could not identify package for model: ${fileName}`);
}
const packageName = splitFile[srcIndex - 1];
const modelName = splitFile[splitFile.length - 2];
// Grab model definitions
const postgresModel =
POSTGRES_DATABASE_MODELS[
modelName as keyof typeof POSTGRES_DATABASE_MODELS
];
const dynamoModel =
DYNAMO_MODEL_DEFINITIONS[
modelName as keyof typeof DYNAMO_MODEL_DEFINITIONS
];
if (postgresModel && dynamoModel) {
throw new Error(
`Found a postgres and dynamodb model with the same name -- please make globally unique: ${modelName}`,
);
}
const modelDefinition = fileName.replace(
'/definition.ts',
`/${modelName}.ts`,
);
let description = '';
if (!existsSync(modelDefinition)) {
console.error(`Expected a model to be defined at: ${modelDefinition}`);
} else {
const fileContents = readFile(modelDefinition);
const comment = GET_CLASS_COMMENT.exec(fileContents);
if (!comment) {
throw new Error(
`Failed to extract class comment in file: ${modelDefinition}`,
);
}
const ast = doctrine.parse(
[`/**${comment[1].split('/**').pop()}`].join('\n'),
{
unwrap: true,
},
);
description = ast.description;
}
if (postgresModel && !postgresModel.definition) {
const detectedGql =
(postgresModel as any).fields && (postgresModel as any).comment;
throw new Error(
`Model ${modelName} missing definition file, ${
detectedGql
? 'but detected GQL schema props.'
: 'did you import the correct file?'
} Ensure you are importing the Wildebeest model into model maps and not the GQL types${
detectedGql ? '' : ' or dynamoDb models'
}`,
);
}
return Object.assign(acc, {
[modelName]: {
packageName,
definitionFilePath: fileName,
modelFilePath: modelDefinition,
dynamoModel,
description,
postgresModel,
},
});
}, {} as IndexedDatabaseModels);
}
/**
* This function generates our `transcend.yml` that is then synced into the Transcend Data Inventory
*
* @see https://app.transcend.io/data-map/data-inventory/data-silos
*
* The function extracts metadata about our database tables and columns, reads in the transcend.yml file
* then writes the updated metadata back to the transcend.yml.
*
* This file is then pushed up using the `transcend inventory push` command
* @see https://github.com/transcend-io/tools/blob/main/packages/cli/README.md#transcend-inventory-push
*/
async function generateTranscendYml() {
const transcendYml = join(MAIN_ROOT, 'transcend.yml');
// Mapping of modelName -> metadata about that model
const modelNameToBaseLocation = indexDatabaseModels();
// Ensure we found definition.ts files for each model
const allModelNames = [
...Object.keys(DYNAMO_MODEL_DEFINITIONS),
...Object.keys(POSTGRES_DATABASE_MODELS),
];
const missingModels = difference(
allModelNames,
Object.keys(modelNameToBaseLocation),
);
const extraModels = difference(
Object.keys(modelNameToBaseLocation),
allModelNames,
);
if (extraModels.length > 0 || missingModels.length > 0) {
console.log({
missingModels,
extraModels,
});
throw new Error(
`Database models are not all accounted for in the generate_mixins file!`,
);
}
// Generate trancsend.yml
const transcendYmlDefinition = readTranscendYaml(transcendYml);
const dataSilos = transcendYmlDefinition['data-silos'] || [];
const titles = dataSilos.map(({ title }) => title);
const postgresDbIndex = titles.indexOf('Postgres RDS Database');
const dynamoDbIndex = titles.indexOf('Dynamo DB Tables');
if (postgresDbIndex < 0 || dynamoDbIndex < 0) {
throw new Error(`Failed to find database definitions in transcend.yml`);
}
const postgres = dataSilos[postgresDbIndex];
postgres.disabled = true;
const dynamo = dataSilos[dynamoDbIndex];
dynamo.disabled = true;
postgres.datapoints = Object.keys(POSTGRES_DATABASE_MODELS).map(
(modelName) => {
try {
const { packageName, description, postgresModel } =
modelNameToBaseLocation[modelName];
if (!postgresModel) {
throw new Error(`Could not find postgres model: ${modelName}`);
}
const schema = Object.keys({
...(postgresModel.definition.attributes || {}),
...Object.entries(
(postgresModel.definition.associations || {}).belongsTo || {},
).reduce(
(acc, [key, value]) =>
Object.assign(acc, {
[typeof value?.foreignKey === 'string'
? value.foreignKey
: value?.foreignKey?.name || `${key}Id`]: true,
}),
{},
),
});
return {
title: modelName,
key: `${packageName}.${modelName}`,
description,
fields:
schema.length > 0
? schema.map((attribute) => ({
key: attribute,
title: attribute,
}))
: undefined,
};
} catch (e) {
console.error(
`Error occurred while generating mixins for ${modelName}`,
);
throw e;
}
},
);
console.success(`Found ${postgres.datapoints.length} datapoints in Postgres`);
dynamo.datapoints = Object.keys(DYNAMO_MODEL_DEFINITIONS).map((modelName) => {
const { packageName, description, dynamoModel } =
modelNameToBaseLocation[modelName];
if (!dynamoModel) {
throw new Error(`Could not find dynamo model: ${modelName}`);
}
const schema = Object.keys((dynamoModel as Schema).schemaObject);
const fields =
schema.length > 0
? schema.map((fieldName) => ({
key: fieldName,
title: fieldName,
}))
: undefined;
return {
title: modelName,
key: `${packageName}.${modelName}`,
description,
fields,
};
});
console.success(`Found ${dynamo.datapoints.length} datapoints in Dynamo`);
// Write out transcend.yml file
writeTranscendYaml(transcendYml, transcendYmlDefinition);
}
generateTranscendYml();Once you've written your script, you can pull this all together with a CI job that runs whenever code is merged into the base branch:
name: Transcend Data Map Syncing
# See https://app.transcend.io/privacy-requests/connected-services
on:
push:
branches:
- 'main'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v2
with:
node-version: '16'
- name: Install Transcend cli
run: npm i -D @transcend-io/cli
# Generate transcend.yml
- name: Generate transcend.yml
run: ./scripts/generate_transcend_yml.py
- name: Push Transcend config
run: npx transcend inventory push --auth=${{ secrets.TRANSCEND_API_KEY }}Another common example you may encounter is the desire to programmatically tag data in your Data Inventory. You may want to do this by:
- Writing some code that transforms your
transcend.ymlfile using the desired auto-tagging rules - Defining a configuration file (e.g.
JSONorYML) that encodes your rules, with a custom script that combines your configuration with yourtranscend.ymlconfiguration.
Step 1) Pull down your transcend.yml for the data systems that you want to manage.
yarn transcend inventory pull --auth=$TRANSCEND_API_KEY --integrationNames=salesforce,googleBigQuerythis produces a transcend.yaml like this:
data-silos:
- title: Postgres RDS Database
integrationName: server
description: Main database that powers the backend monolith
datapoints:
- title: Team
key: access-control-models.team
description: A team of users sharing the same scopes
fields:
- key: description
description: The description of the team
title: description
- key: name
description: The name of the team
title: name
- title: User
key: access-control-models.user
description: A user to the admin dashboard
fields:
- key: createdAt
description: null
purposes: []
access-request-visibility-enabled: true
erasure-request-redaction-enabled: true
categories: []
- key: email
description: null
purposes: []
access-request-visibility-enabled: false
erasure-request-redaction-enabled: true
categories:
- name: Email
category: CONTACT
- key: isAdmin
title: isAdmin
- key: isInviteSent
title: isInviteSent
- key: email
title: email
description: The email of the user
- key: name
title: name
- key: onboarded
title: onboardedStep 2) Define a separate configuration file containing your rules
# rules for automatically tagging datapoints
# with specific data categories if the datapoint name
# follows a certain format
- datapoint-data-categories:
- column_name: email
category_name: email
category: CONTACT
# rules for automatically tagging data subject
# whenever a datapoint is tagged with a specific data category
- datapoint-data-subjects:
- category: CONTACT
category_name: Government Email
data_subject: Government UserStep 3) Write the custom script to update your transcend.yml configuration according to these rules. Here is a brief prompt asking ChatGPT to provide such a script.
Step 4) You could set up this script to automatically run
name: Transcend Data Inventory Auto Tagging
# See https://app.transcend.io/privacy-requests/connected-services
on:
# Run daily
schedule:
- cron: '0 16 * * *'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v2
with:
node-version: '16'
- name: Install Transcend cli
run: npm i -D @transcend-io/cli
- name: Pull Transcend config
run: npx transcend inventory pull --auth=${{ secrets.TRANSCEND_API_KEY }}
- name: Generate transcend.yml
run: ./scripts/generate_transcend_yml.py
- name: Push Transcend config
run: npx transcend inventory push --auth=${{ secrets.TRANSCEND_API_KEY }}The Transcend GraphQL API is the most flexible way to push data into Transcend. This is the same API that Transcend's Admin Dashboard uses, so any query or filter you can make in the Transcend Dashboard is also available in this API.
To start:
- Generate an API key in the Transcend Dashboard. You will need to assing the API key scopes. These scopes will vary depending on which resource types you intend to push.
- Run the CLI command in your terminal to export your Data Inventory to a yml file.
To start, go into the Transcend Admin Dashboard to create an API key.
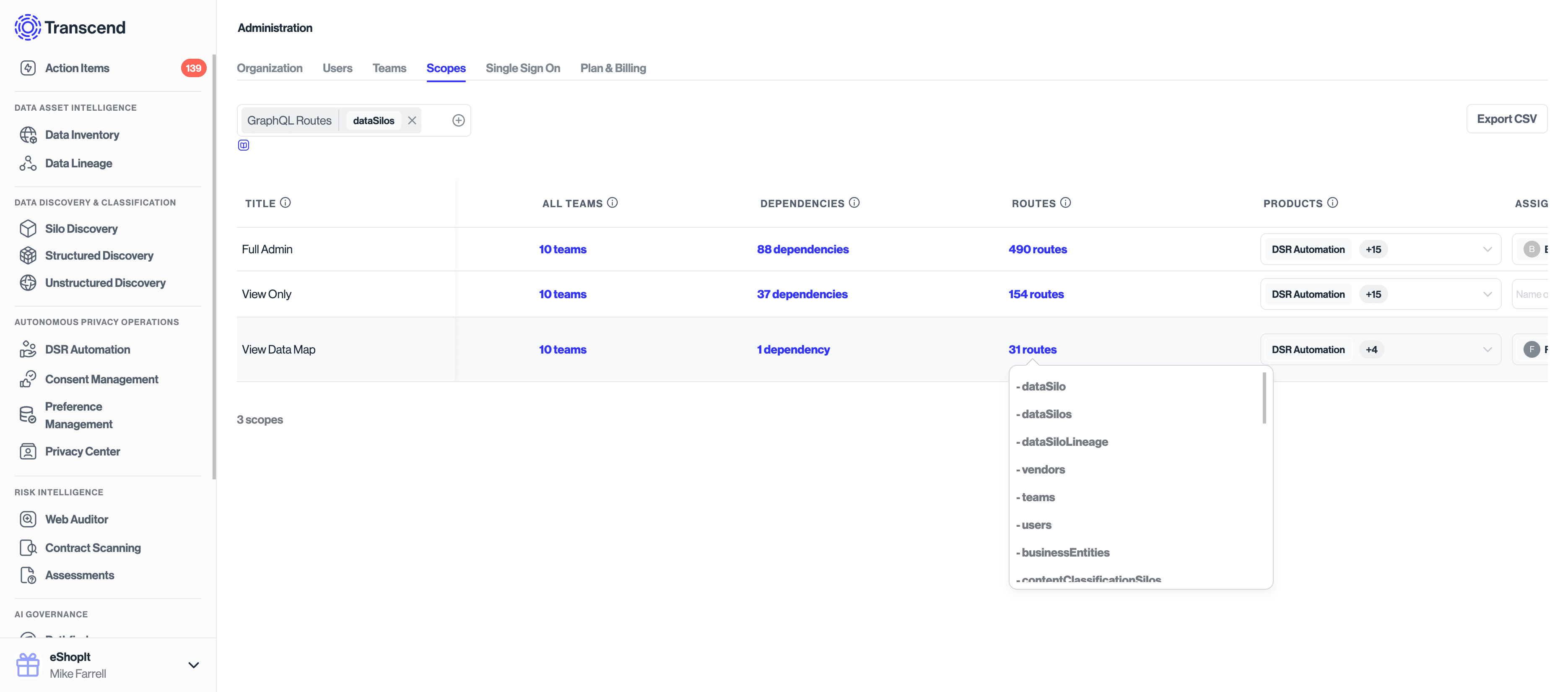
The scopes that you will grant to the API key will depend on the routes you plan to use. You can visualize the relationship between Scopes and GraphQL Routes on the Scopes tab of the Admin Dashboard.
GraphQL APIs have a lot of great open source development tooling built around them. You can call the GraphQL API with any standard request tooling, however you find it nice to use a GraphQL client package within the language of your choice. For example see graphql-request for JavaScript.
You would instantiate your GraphQL client providing the API key as a bearer token.
import { GraphQLClient } from 'graphql-request';
const transcendUrl = 'https://api.transcend.io'; // for EU hosting
// const transcendUrl = 'https://api.us.transcend.io'; // for US hosting
const client = new GraphQLClient(`${transcendUrl}/graphql`, {
headers: {
Authorization: `Bearer ${process.env.TRANSCEND_API_KEY}`,
},
});Once you've created your GraphQL client, the next step is to create the GraphQL that pushes the data that you care to export. The best way to do this is using the GraphQL playground to construct and test your payload. You will first what to make sure that you are logged in to the Transcend Admin Dashboard and if you have multiple Trancsend accounts, ensure that you have switched into the correct account.
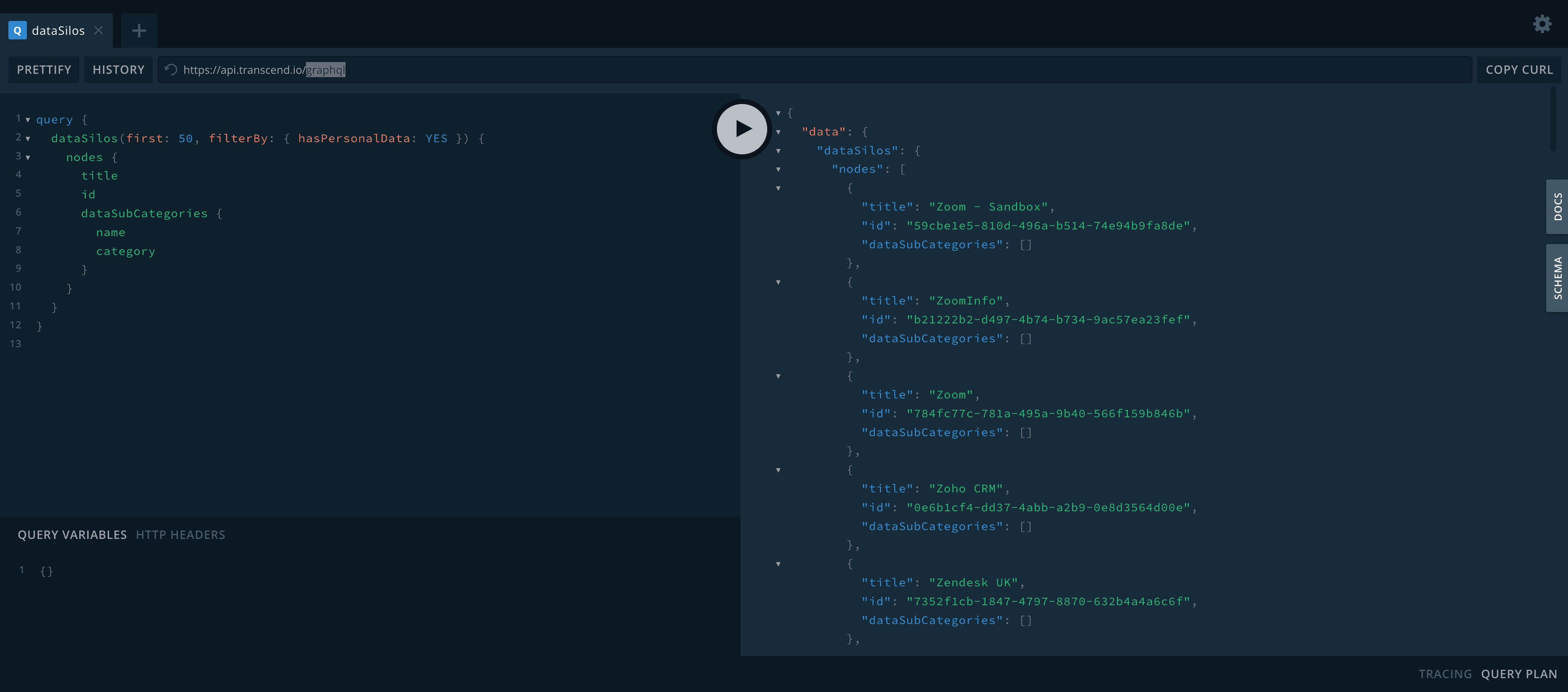
You can then navigate to either the Default EU Hosted GraphQL Playground or the US Hosted GraphQL Playground.
On the right hand side of the screen, you can open up the "Docs" tab to view all of the GraphQL routes avilable, and all of the input/output document types.
You should use the GraphQL playground to get the most up to date set of parameters for each Data Inventory routes. GraphQL gives you the ability to specify exactly which fields you want to pull. By specifying the minimal set of parameters in the API, you will achieve faster request times.
To understand the useful API calls for pulling data and IDs from the Transcend Data Inventory, check out this article to see some example GraphQL calls for reading data from the Data Inventory.
Some good starting points for GraphQL mutations include:
mutation DataInventoryGraphQLExampleUpdateDataSilos {
updateDataSilos(
input: {
dataSilos: [
{ id: "2b9396b0-7061-4aed-9c70-44fd8cb50d2f", description: "My Bucket" }
]
}
) {
clientMutationId
dataSilos {
id
title
description
}
}
}This may produce an output like
{
"data": {
"updateDataSilos": {
"clientMutationId": null,
"dataSilos": [
{
"id": "2b9396b0-7061-4aed-9c70-44fd8cb50d2f",
"title": "Amazon.com",
"description": "My Bucket"
}
]
}
}
}mutation DataInventoryGraphQLExampleUpdateVendors {
updateVendors(
input: {
vendors: [
{
id: "fbe81d3d-e2f5-4d28-bf4b-11884328c724"
description: "My new description"
}
]
}
) {
clientMutationId
vendors {
id
title
description
}
}
}This may produce an output like
{
"data": {
"updateVendors": {
"clientMutationId": null,
"vendors": [
{
"id": "fbe81d3d-e2f5-4d28-bf4b-11884328c724",
"title": "15Five, Inc.",
"description": "My new description"
}
]
}
}
}mutation DataInventoryGraphQLExampleUpdateDataCategories {
updateDataSubCategories(
input: {
dataSubCategories: [
{
id: "e0945fda-6c34-4766-80ef-b454ad77b728"
teamNames: ["Developers"]
}
]
}
) {
clientMutationId
dataSubCategories {
id
name
description
}
}
}This may produce an output like:
{
"data": {
"updateDataSubCategories": {
"clientMutationId": null,
"dataSubCategories": [
{
"id": "e0945fda-6c34-4766-80ef-b454ad77b728",
"name": "",
"description": "Generic health information"
}
]
}
}
}mutation DataInventoryGraphQLExampleUpdateProcessingPurposes {
updateProcessingPurposeSubCategories(
input: {
processingPurposeSubCategories: [
{ id: "4586c6ee-9142-4d4b-9851-aaafbd56ba9d", description: "test" }
]
}
) {
clientMutationId
processingPurposeSubCategories {
id
name
description
}
}
}This may produce an output like:
{
"data": {
"updateProcessingPurposeSubCategories": {
"clientMutationId": null,
"processingPurposeSubCategories": [
{
"id": "4586c6ee-9142-4d4b-9851-aaafbd56ba9d",
"name": "",
"description": "test"
}
]
}
}
}mutation DataInventoryGraphQLExampleUpdateBusinessEntities {
updateBusinessEntities(
input: {
businessEntities: [
{ id: "88b067a8-cc02-483e-a44b-8caeafb41c5e", description: "test" }
]
}
) {
clientMutationId
businessEntities {
id
title
description
}
}
}This may produce an output like:
{
"data": {
"updateBusinessEntities": {
"clientMutationId": null,
"businessEntities": [
{
"id": "88b067a8-cc02-483e-a44b-8caeafb41c5e",
"title": "Acme",
"description": "test"
}
]
}
}
}mutation DataInventoryGraphQLExampleUpdateIdentifier {
updateIdentifier(
input: { id: "717284bc-1b17-4543-bc32-0d64aafe12d6", placeholder: "test" }
) {
clientMutationId
identifier {
id
placeholder
}
}
}This may return a result like:
{
"data": {
"updateIdentifier": {
"clientMutationId": null,
"identifier": {
"id": "717284bc-1b17-4543-bc32-0d64aafe12d6",
"placeholder": "test"
}
}
}
}mutation DataInventoryGraphQLExampleUpdateDataSubject {
updateSubject(
input: { id: "2b882d1e-430a-4b37-a6e8-067e18b101d6", title: "New Customer" }
) {
clientMutationId
subject {
id
title {
defaultMessage
}
}
}
}This my return a result like:
{
"data": {
"updateSubject": {
"clientMutationId": null,
"subject": {
"id": "2b882d1e-430a-4b37-a6e8-067e18b101d6",
"title": {
"defaultMessage": "New Customer"
}
}
}
}
}Once you have your GraphQL query constructed, you will want to define it as a constant in your code. For example:
import { gql } from 'graphql-request';
const UPDATE_DATA_SILOS = gql`
mutation DataInventoryGraphQLExampleUpdateDataSilos(
$input: UpdateDataSilosInput!
) {
updateDataSilos(input: $input) {
clientMutationId
dataSilos {
id
title
description
}
}
}
`;You then will want to use your GraphQL client from Step 2) to make this request:
const paged = await client.request(UPDATE_DATA_SILOS, {
input: {
dataSilos: [
{
id: '2b9396b0-7061-4aed-9c70-44fd8cb50d2f',
description: 'My Bucket',
},
],
},
});