Connecting Data Stores
Structured Discovery helps you identify and classify personal data within your data systems. Before you can use this feature, you'll need to connect your data stores to Transcend. This guide explains how to connect different types of data sources.
To connect an internal database for Structured Discovery:
-
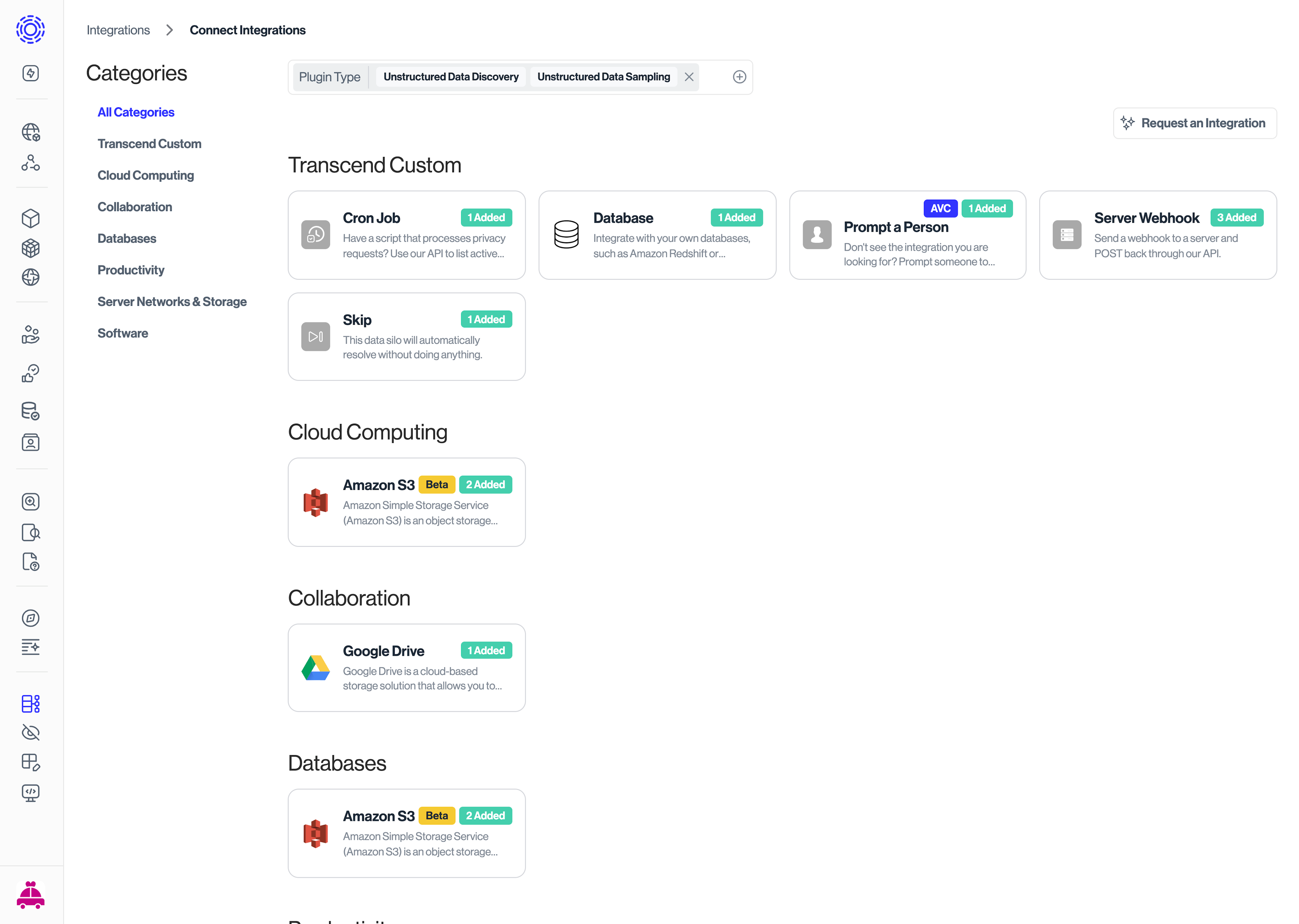
Navigate to Infrastructure > Integrations in the left sidebar
-
Click Add Integration
-
Search for and select your database type (PostgreSQL, MySQL, etc.)
-
On the integration details page, go to the Connection tab
-
Click Connect and enter your database credentials:
- Server address and port
- Database name
- Username and password (or other authentication details)
- Connection options (SSL, etc.)
-
After connecting, go to the Structured Discovery tab of the integration
-
Enable both the Datapoint schema discovery and Datapoint classification plugins
-
Return to the Structured Discovery page to view your scan results
Alternative approach: You can also add data silos directly from the Structured Discovery page:
- Navigate to Data Inventory > Structured Discovery
- Click Add Database
- Select your database type and click Add
- Click View Database to open the integration details
- Follow the connection steps as described above
Connecting SaaS applications follows a similar process:
-
Navigate to Infrastructure > Integrations
-
Click Add Integration
-
Search for and select your SaaS tool (e.g., Salesforce, HubSpot)
-
Follow the connection instructions, which typically involve:
- Authorizing via OAuth
- Entering API credentials
- Granting necessary permissions

-
Once connected, go to the Structured Discovery tab of the integration
-
Enable both the Datapoint schema discovery and Datapoint classification plugins
After connecting your data stores, Structured Discovery will begin scanning and classifying your data automatically. The initial scan may take some time depending on the size and complexity of your data.