Scanning AWS Data Stores with Structured Discovery
Once all of the AWS data stores & systems are identified and added to Data Inventory, the next step is understanding what data is stored in each and the purpose of that data.
In addition to the global AWS Silo Discovery integration, Transcend has separate integrations with each AWS service that gets discovered. Once the relevant data silos have been discovered, each one can be enabled for datapoint schema discovery & datapoint classification.
The S3 integration supports Structured Discovery to programmatically create datapoints in Transcend that represent pieces of data in S3. When enabled, the plugin scans the AWS account to identify all S3 buckets using the listBuckets command. Each bucket found is recommended as a datapoint, and a new datapoint is surfaced when new buckets are created. Each datapoint discovered is classified as to the type of data it represents to help customers identify which datapoints may contain personal information and which don’t.
Additionally, if you have S3 buckets that are holding Parquet files or JSON files, you can use either the S3 Parquet or S3 JSONL Integration to index the schemas of those files as if you were indexing a proper SQL or no-SQL Database. When you configure and enable one S3 integration in Transcend, this will scan all buckets the credentials you entered has access to, and count as one integration.
The DynamoDB integration can be enabled for datapoint schema discovery as well. The integration will scan for all tables using the ListTables method and recommend each table as a datapoint, and get the attributes for each table using DescribeTable and surface them as sub-datapoints. The discovered sub-datapoints are classified through Structured Discovery. Remember that if the DynamoDB silo was discovered through the AWS integration scan, the silo is scoped to a single AWS region and not a single Dynamo Table.
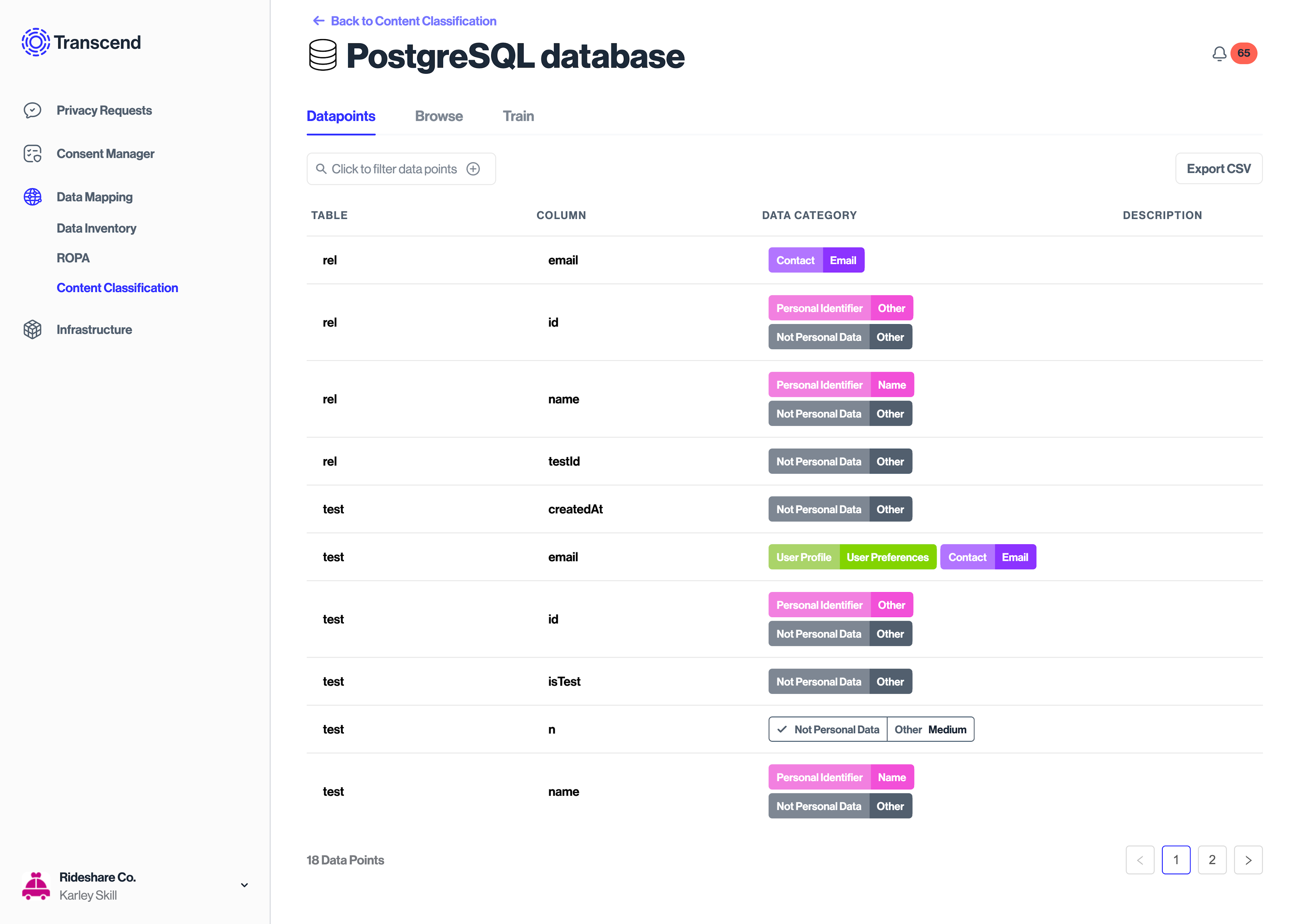
Structured Discovery for the database integrations works similarly to the DynamoDB integration. Database data silos discovered & added during an AWS integration scan can be enabled for datapoint schema discovery and classification. Each table in the database will correspond to a recommended datapoint, and the columns on each table will correspond to sub-datapoints for the database silo. Discovered sub-datapoints are classified through Structured Discovery to help customers prioritize datapoints that may contain personal information.
More information about the database integration can be found here.
Before starting, please ensure you've set up the AWS integration based on the steps in our guide.
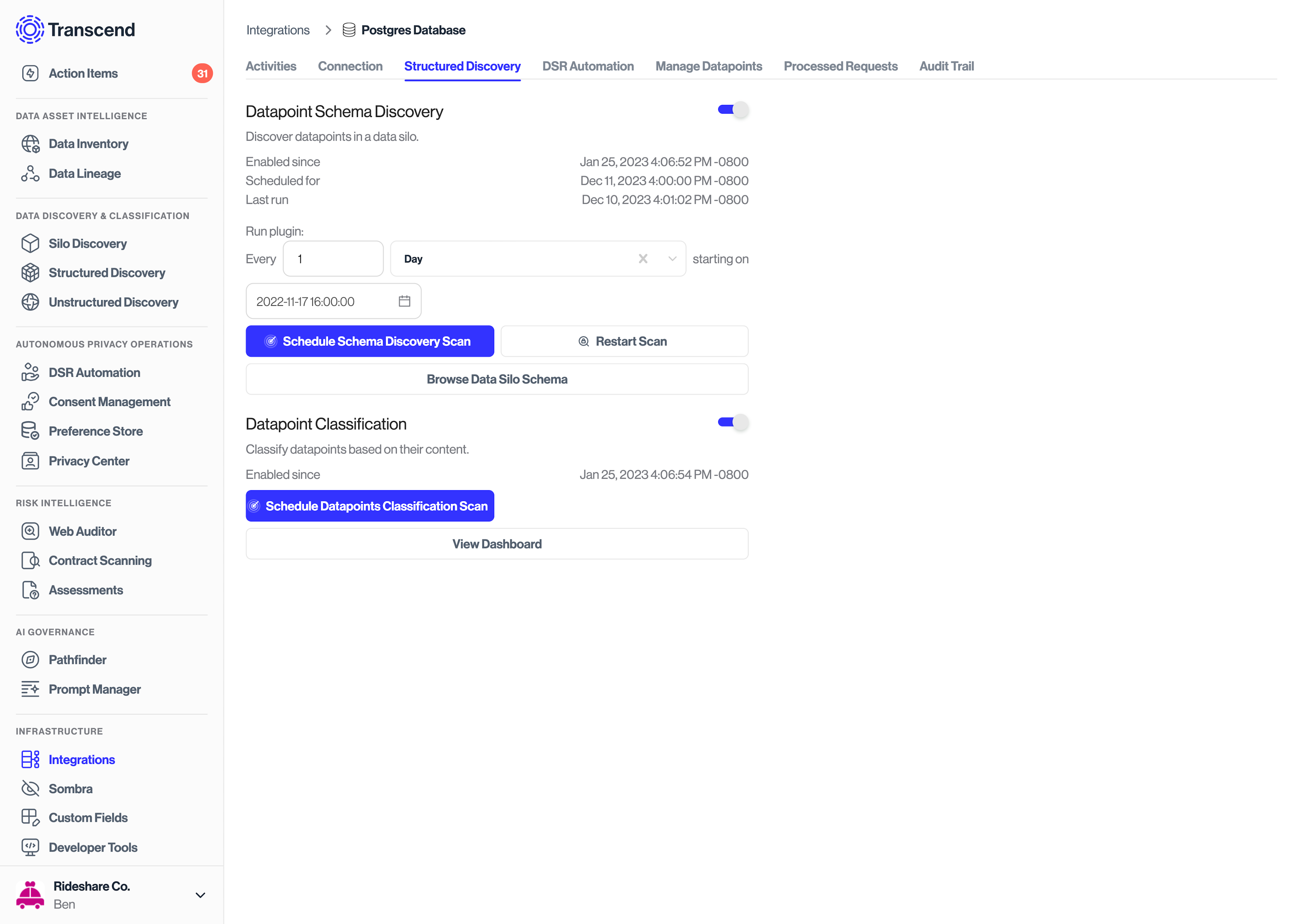
Once a discovered data silo has been approved and added to Data Inventory, it can be configured to further scan the individual resources to identify and classify information stored within. To enable Structured Discovery for a resource, simply navigate to the Structured Discovery tab of desired integration and enable the Datapoint Schema Discovery plugin.
The plugin works by scanning a resource or system to identify datapoints within the system and classify them. The example below shows a scan of a PostgreSQL database discovered by the AWS plugin. In this case the plugin scans the tables in the database, and recommends a datapoint for every column in each table.