Amazon S3 Plugins Configuration
Please ensure you have connected an Amazon S3 integration before continuing with this guide.
Once the integration is connected, enable the Datapoint schema discovery plugin to start scanning AWS. You can also schedule when to run the next scan.
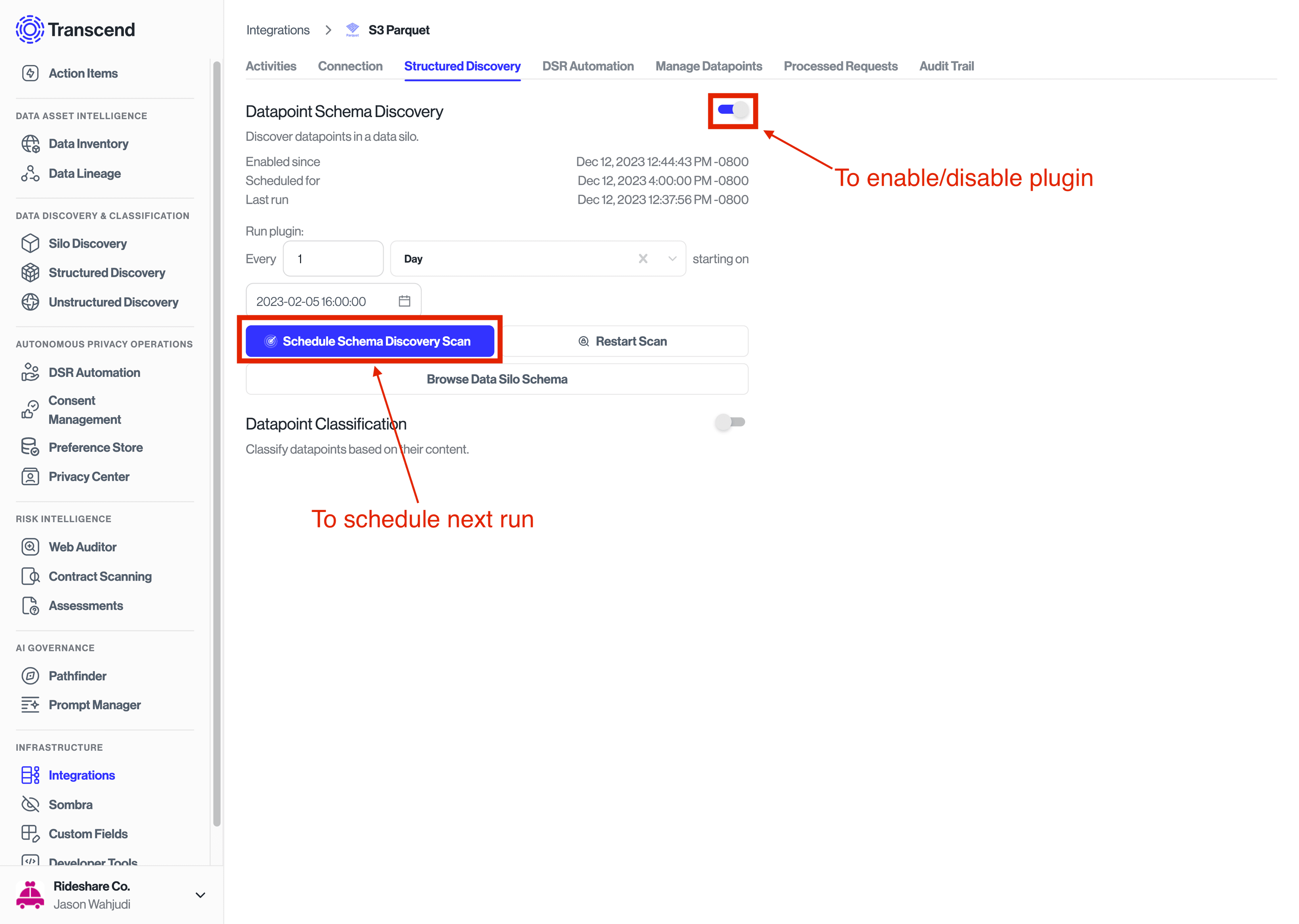
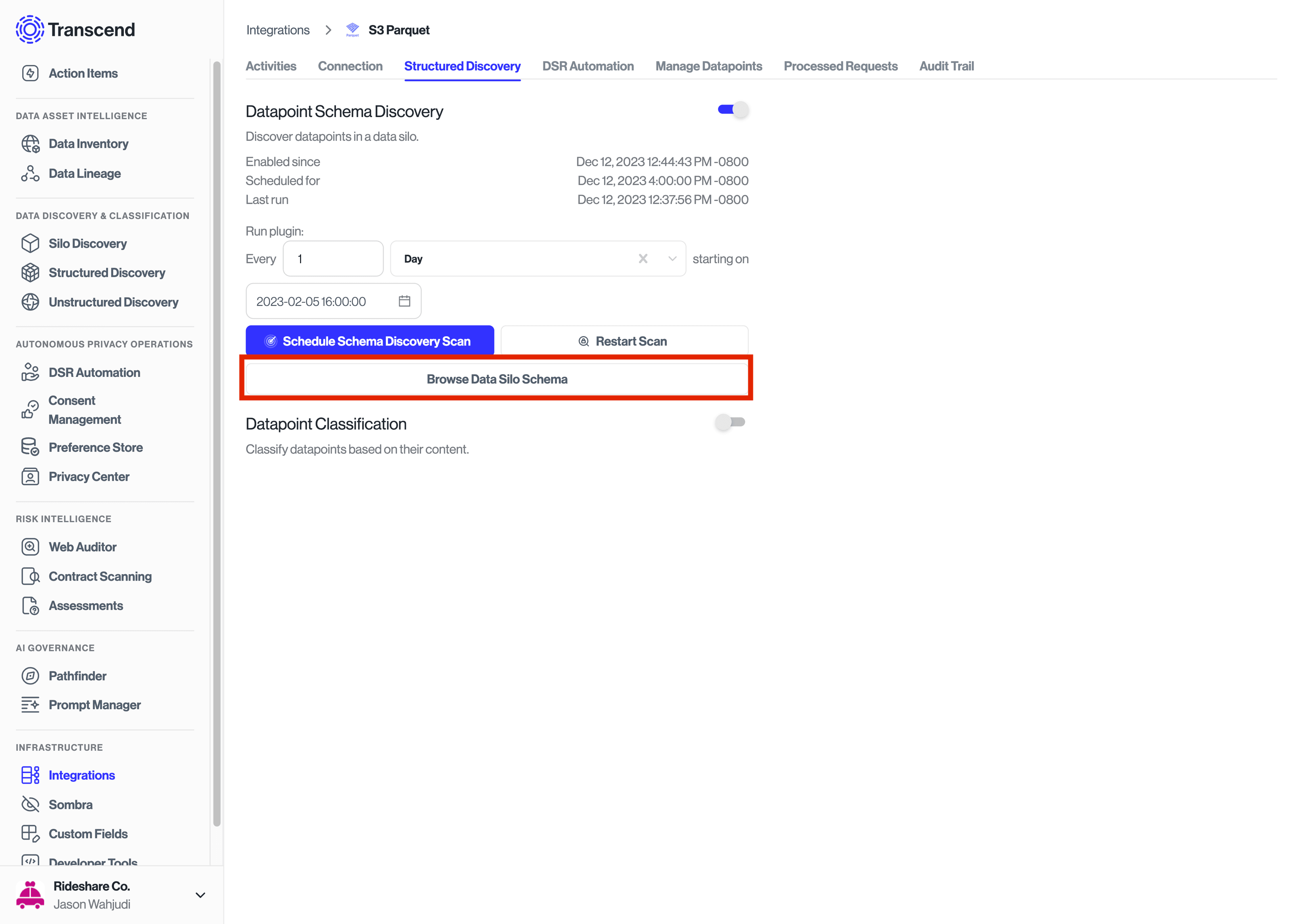
Once the scan is complete, select Browse Data System Schema to review and approve the discovered datapoint.
Unstructured data in S3 can be classified using our unstructured content classification system.
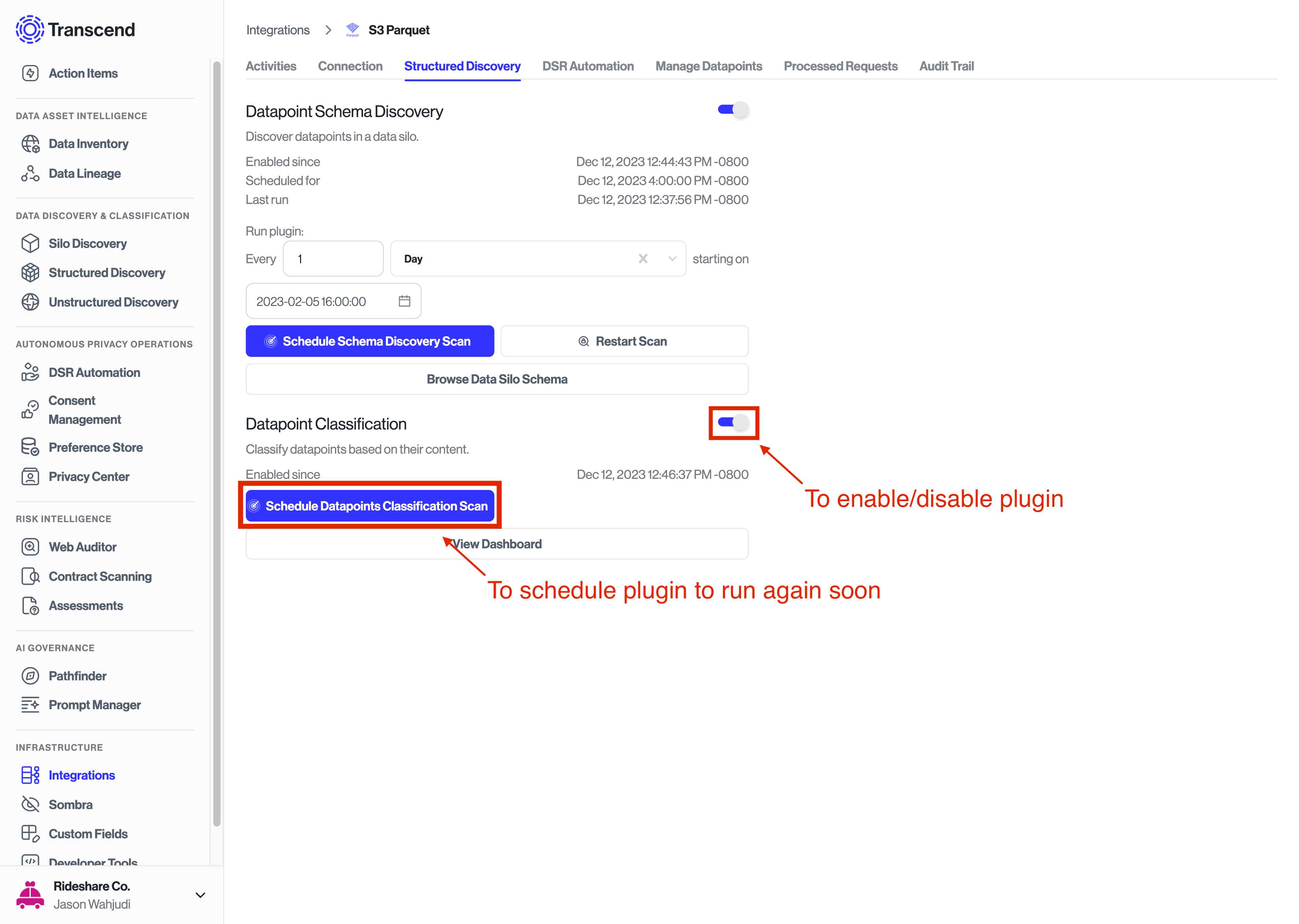
For structured data, particularly JSONL or Parquet, you can also enable Datapoint classification. When this plugin runs, it will read samples of data from the discovered dataPoints, then suggest data categories that you can tag them with.
Check out our full Data Classification guide for more information about how it works.
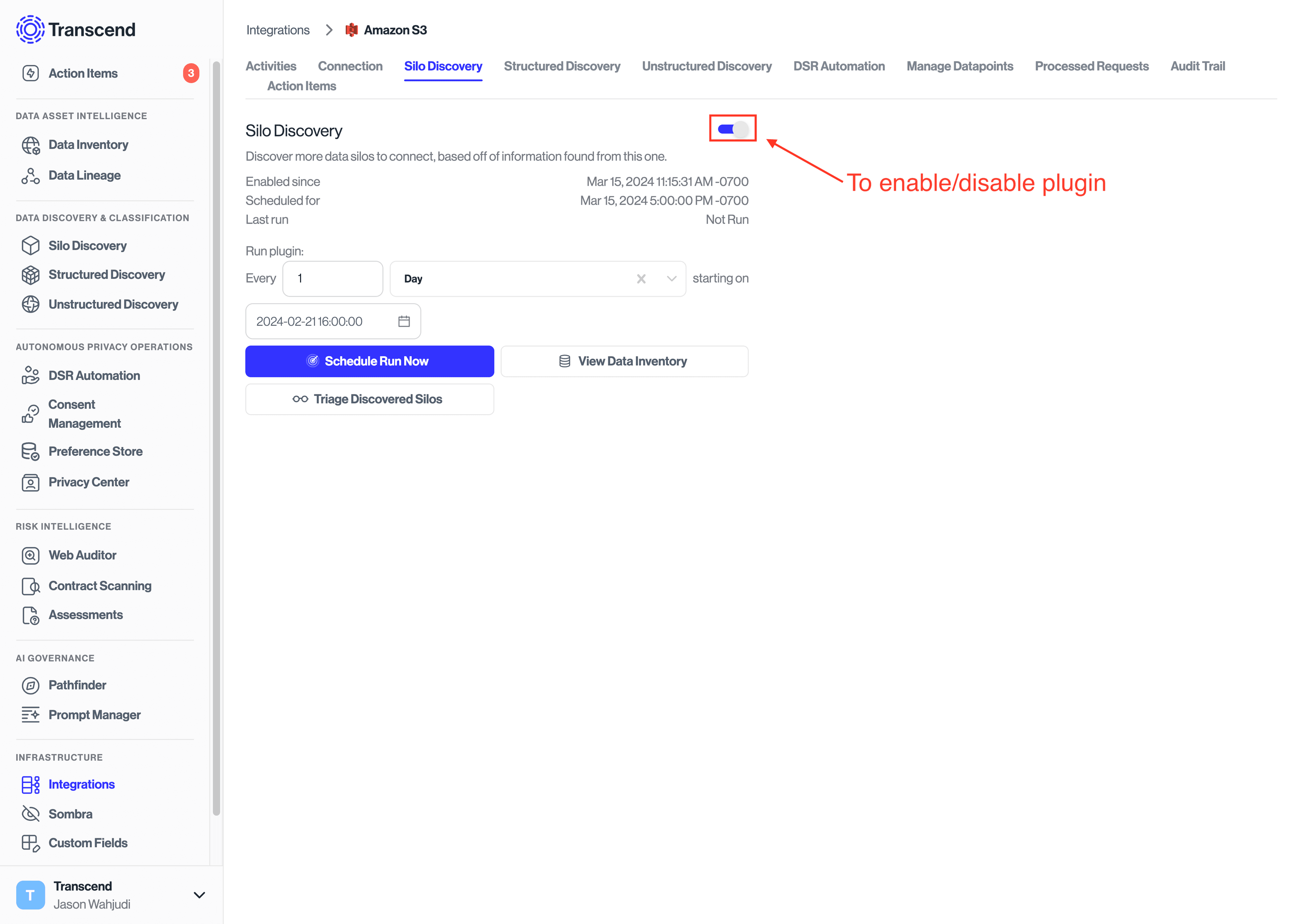
In addition to Structured Discovery, you can also run a Data System Discovery in the Amazon S3 Integration in order to determine whether an additional S3 Parquet or S3 JSONL integration is recommended, by checking if the buckets contains any Parquet or JSON file.
Similar to the Structured Discovery, connect the integration first and then enable the System Discovery to start scanning for the additional S3 integrations.
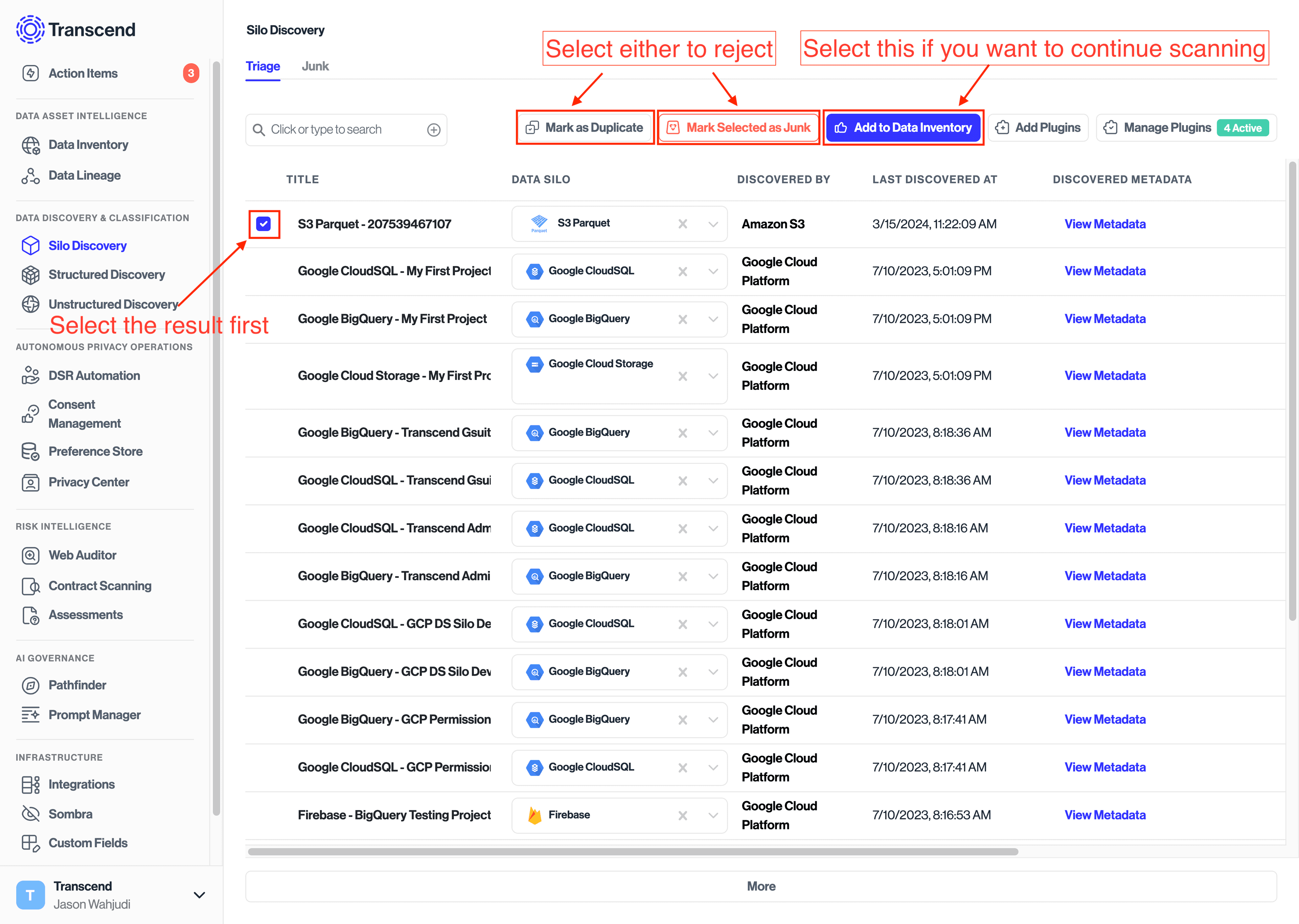
To look at the results, you can click on the Triage Discovered Systems, which would display the integrations. From there, you can either add the Data System or reject it.