Database Integration Set Up for DSR Automation
With the Transcend Database integration, you can fulfill DSRs directly against a Database by running SQL queries.
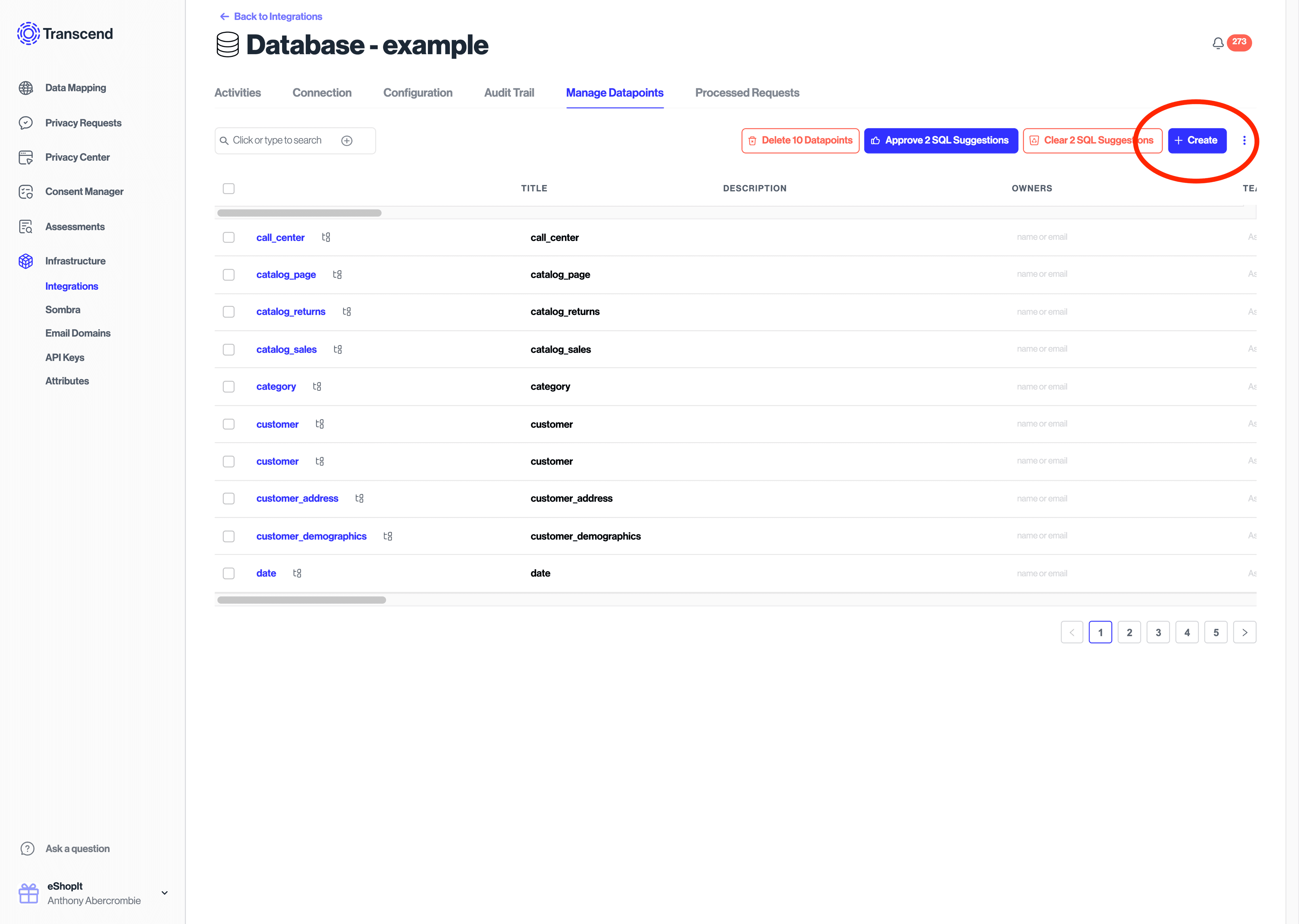
In Infrastructure / Integrations, select the database of interest. On the Manage Datapoints page, you will find the tables in the database as datapoint. Datapoints can be discovered automatically by enabling the Datapoint Schema Discovery plugin for the integration or by manually creating datapoints in this interface.
When you write custom SQL — whether in the Prepared Statement field of a datapoint DSR action, in a preflight database enrichment SQL query, or in a consent workflow SQL trigger — Transcend lets you reference the data subject's identifier and any context from the inbound DSR by templating variables into your SQL. The same variable set is available in every SQL editor that targets a database integration. Variables are resolved per-request and bound through prepared-statement parameters when possible, so you never need to worry about quoting or escaping the values yourself.
Three placeholder syntaxes are supported and produce identical results:
| Syntax | Meaning | Example |
|---|---|---|
@variableName | Named-parameter form (identifier and request-context variables only) | WHERE email = @email |
{{variableName}} | Template-variable form | WHERE email = {{email}} |
| ? | Positional placeholder — always binds the identifier value for the data point | WHERE email = ? |
You can mix and match all three in the same statement. Customer-supplied values flow through ODBC prepared-statement bind, never string interpolation, so SQL injection is not a concern.
The most common variable is the identifier value — the email/phone/userId/etc. that the DSR is looking up. The variable name is configurable per integration (see Integrations → <Integration> → DSR Automation → Identifiers); All three of these are equivalent and resolve to the data subject's identifier:
-- Bare positional (legacy convention — every `?` is the identifier)
SELECT * FROM users WHERE email = ?;
-- Named (replace 'email' with whatever your data silo's identifier type is)
SELECT * FROM users WHERE email = @email;
-- Template form
SELECT * FROM users WHERE email = {{email}};The same identifier value can appear multiple times in one statement — for example, when matching against several columns:
SELECT * FROM users WHERE email = @email OR alt_email = @email OR LOWER(login_email) = LOWER(@email);Every DSR carries metadata about the request itself. These variables are available in every SQL statement:
| Variable | Type | Description | Example Value |
requestId | string | The unique UUID of the privacy request | "1d50baa0-7409-43e8-baa2-7283d0fc4f7e" |
requestType | string | The action type | "ACCESS", "ERASURE", "CONTACT_OPT_OUT", "CUSTOM_OPT_IN", etc. |
requestCreatedAt | string | ISO 8601 timestamp of request submission | "2026-05-26T20:14:33.000Z" |
requestLocale | string | Locale code submitted with the request | "en-US" |
requestDetails | string | Free-text details supplied by the data subject | "Please remove all marketing data" |
requestIsTest | boolean | true if the request was submitted in test mode | 0, 1 |
requestOrigin | string | Origin of the request | "PRIVACY_CENTER", "API", "ADMIN_DASHBOARD", etc. |
requestDataSubjectType | string | The data subject type slug | "customer", "employee" |
requestCountry | string | null | ISO 3166-1 alpha-2 country code | "US" |
requestCountrySubDivision | string | null | ISO 3166-2 subdivision code | "US-CA" |
requestPrimaryEmailValue | string | null | The primary email associated with the request, when known | "alice@example.com" |
consentPurposeTriggerSlug | string | null | For consent-workflow-triggered DSRs, the purpose slug that triggered the workflow | "Marketing" |
consentPurposeTriggerValue | boolean | null | The new consent value that triggered the workflow | false |
partitionId | string | null | The partition the request was filed under | "1bf15936-d4e1-43bc-8322-606c1afa34a4" |
partitionName | string | null | Human-readable partition name | "EU Production" |
Tag every audit-log row with the DSR ID so you can correlate later:
INSERT INTO dsr_audit (email, request_id, action, requested_at)
VALUES ({{email}}, {{requestId}}, {{requestType}}, {{requestCreatedAt}});Preflight enricher — find every user_id associated with a customer's email and pass each one downstream as a new identifier:
-- Configured as an database preflight check with input identifier "email" and
-- output identifier "userId"
SELECT user_id AS "userId"
FROM customers
WHERE LOWER(email) = LOWER({{email}});Skip the rest of an erasure if the request was submitted in test mode:
DELETE FROM users WHERE email = {{dsr_identifier_value}} AND NOT {{requestIsTest}};Filter by region (useful for partitioned data warehouses):
SELECT * FROM customer_records WHERE customer_id = {{email}} AND region_code = {{requestCountry}};Every request attribute / custom field defined on your Transcend organization automatically becomes a templatable variable named customField_<camelCaseAttributeKey>. The attribute key is camelCased — e.g. an attribute named Audit Reason becomes customField_auditReason.
INSERT INTO dsr_audit (email, audit_note, requester_team)
VALUES (
{{email}},
{{customField_auditNote}},
{{customField_requesterTeam}}
);If the attribute is multi-select, the value is bound as a JSON array string (e.g. '["a","b"]') — use PARSE_JSON() (Snowflake), '::JSONB' (Postgres), or your driver's equivalent to access individual elements.
For DSRs triggered by consent workflows, every consent preference defined on the triggering purpose is exposed as consentPreference_<preferenceSlug>. Boolean preferences are inlined as SQL TRUE/FALSE; multi-select preferences are bound as JSON-array strings.
UPDATE marketing_subscriptionsSET email_opt_in = {{consentPreference_marketingEmail}}, sms_opt_in = {{consentPreference_marketingSms}} WHERE email = {{email}};null and boolean variables are inlined as SQL literals rather than bound, because ODBC parameter binding is not portable across drivers for those types. Specifically:
null→NULL(a real SQL NULL — comparisons likeIS NULLwork as expected).true→TRUE.false→FALSE.
Quoted placeholders are also handled: if you write '{{requestLocale}}' and requestLocale is null, the surrounding quotes are stripped and the result is the SQL NULL literal (not the string 'null').
Amazon Redshift's query planner refuses to resolve untyped expressions in a SELECT projection (Invalid type: 705 / Unreachable - tbl_trans.hpp errors). When you project a templated variable directly as a column — especially {{requestLocale}}, {{customField_*}}, {{requestId}}, or anything that might resolve to NULL — wrap it in an explicit cast:
SELECT
email,
{{requestIsTest}}::BOOLEAN AS is_test,
{{customField_audit}}::VARCHAR AS audit_note,
{{requestLocale}}::VARCHAR AS locale,
{{requestId}}::VARCHAR AS rid
FROM usersWHERE email = ?;Snowflake, Postgres, MySQL, and the other supported drivers tolerate the untyped form, so the cast is only strictly required on Redshift — but it's portable across all of them and a good habit if you may run the same SQL against multiple silos.
The following databases support all variables described above:
- Snowflake
- PostgreSQL
- Amazon Redshift
- MySQL
- MariaDB
- IBM DB2
- Oracle
- Azure Synapse
- Databricks Lakehouse
- Google Cloud Spanner
The following databases support only Identifier + requestId
- Microsoft SQL Server
- Google BigQuery
- MongoDB
- DynamoDB (PartiQL)
- Google Bigtable
The following databases only support identifier variables:
- Azure Cosmos DB (NoSQL)
- Elasticsearch
For drivers with partial support, you can still use the identifier (?, @email, {{email}}) and {{requestId}} in both preflight enricher and datapoint SQL, but referencing any other variable will leave the placeholder text in your query and cause a SQL parse error. If you need full variable support on one of those drivers for either preflight or datapoint queries, contact your Transcend account team.
Template variables are evaluated by your Sombra gateway, which sees both preflight enricher queries and per-datapoint DSR queries on the same proxyDatabase route. The minimum Sombra versions below apply to both flows — there is no separate version for enricher vs. datapoint use:
| Variable family | Minimum Sombra version |
|---|---|
? and {{requestId}} (legacy) | Available in all current Sombra versions |
{{customField_*}}, {{consentPreference_*}}, all request context variables (Databricks Lakehouse) | 7.469.18 |
{{customField_*}}, {{consentPreference_*}}, all request context variables (Snowflake / Postgres / Redshift / MySQL / MariaDB / DB2 / Oracle / Azure Synapse) | 7.510.0 |
{{customField_*}}, {{consentPreference_*}}, all request context variables (Google Cloud Spanner) | 7.479.0 |
| Pitfall | What happens | How to fix |
|---|---|---|
| Referencing a variable that doesn't exist | Sombra returns a Found named params with no provided values error before the query runs | Check spelling and casing — customField_* keys are camelCase; consent preferences use the preference slug exactly |
Wrapping a variable in quotes ('{{requestId}}') | Generally unnecessary — variables are bound as parameters, so quoting is handled by the driver | Use {{requestId}} (no quotes); Transcend will quote string values for you |
Relying on customField_* for a custom field that isn't set on the request | The variable resolves to an empty value and your query may behave unexpectedly | Mark the custom field as required on the request form, or add a COALESCE / CASE WHEN to your SQL |
Using {{var}} syntax on Microsoft SQL Server or Google BigQuery for non-identifier variables | The placeholder is left in the SQL and the driver returns a parse error | Stick to ? / {{dsr_identifier_value}} / {{requestId}} on those drivers until full support lands |
The property settings column in the Manage Datapoints interface will allow you to view the columns of each datapoint table and assign each column a category of personal data. This process of assigning categories to columns will enable Transcend to generate access and erasure SQL statements for you automatically.
In this view the Access Request Visibility toggle determines whether a SELECT * statement or SELECT <field> statement.
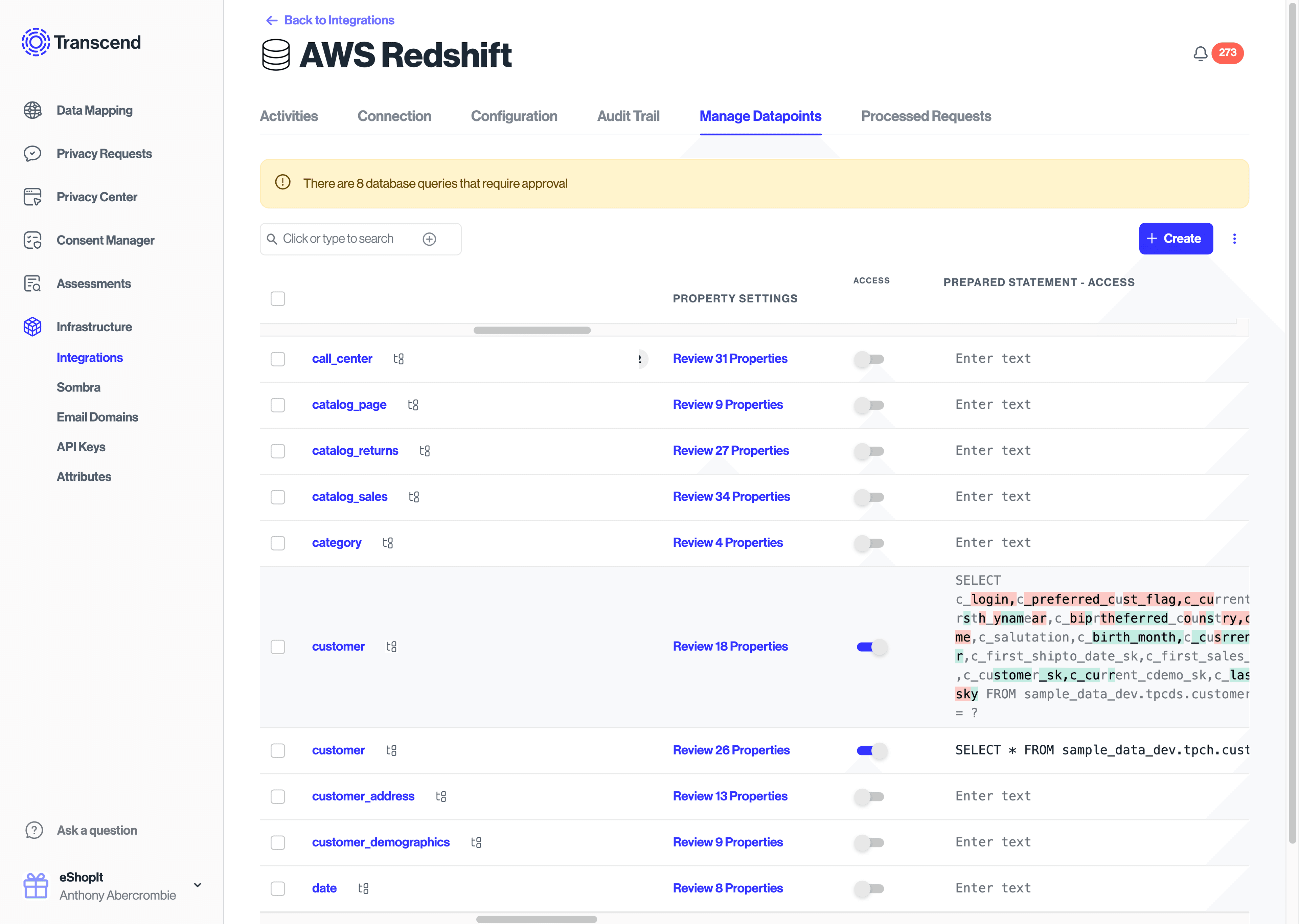
The Erasure Properties to Redact toggle determines whether the erasure request is a DELETE or UPDATE statement.
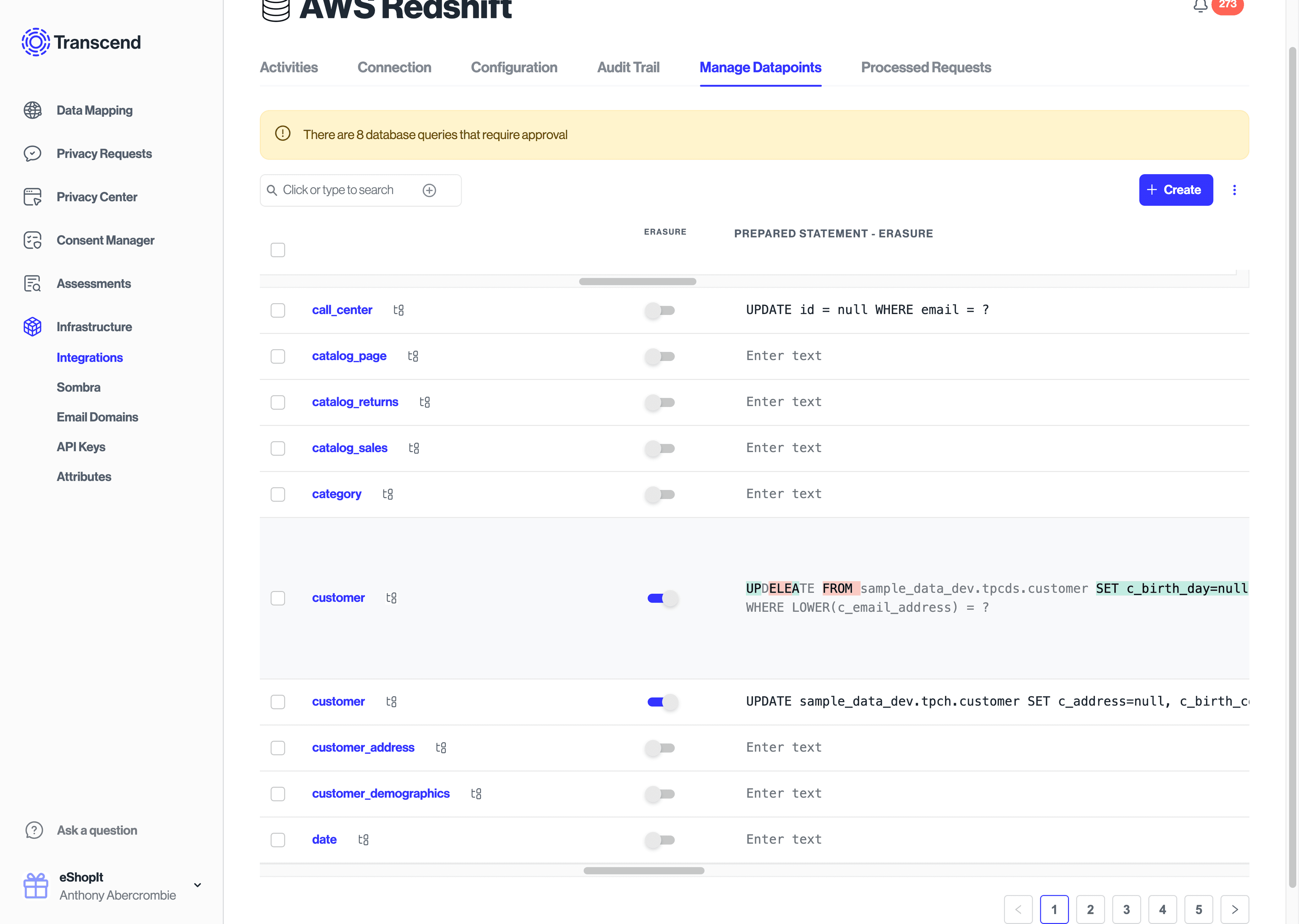
Categories can also be set in the Structured Discovery / Datapoints interface by editing the Data Categories column. If a datapoint is declared as Personal Identifier User ID, Contact Email, or Contact Phone, then the same autogeneration of SQL statements can be applied for various DSR types.
You also have the option of manually setting SQL queries for each table in the Prepared Statement column text fields. This can be used to facilitate more complex queries e.g. joining two tables for an enrichment.
SQL statements for facillitating DSR Automation can also be configured in code using Transcend's CLI.
The workflow involves:
1. Using the transcend inventory pull command to pull existing SQL statements down from your Transcend instance into a trancend.yml file.
yarn transcend inventory pull --auth=$TRANSCEND_API_KEY --dataSiloIds=965b0eb2-b87d-464c-a849-571e31384001 --resources=dataSilos- Edit the SQL commands in
transcend.yml. See this example. - Commit and push your changes using the
transcend inventory pushcommand
To use this workflow, the required scopes for your Transcend API Key are:
Manage Data InventoryManage Data Subject Request SettingsManage API Keys
Once you have a workflow for updating and publishing SQL statements using the CLI, you may want to automate this process using CI. Here is an example for how to accomplish this using a GitHub Action.
Instructions for manually submitting DSRs can be found in this documentation.
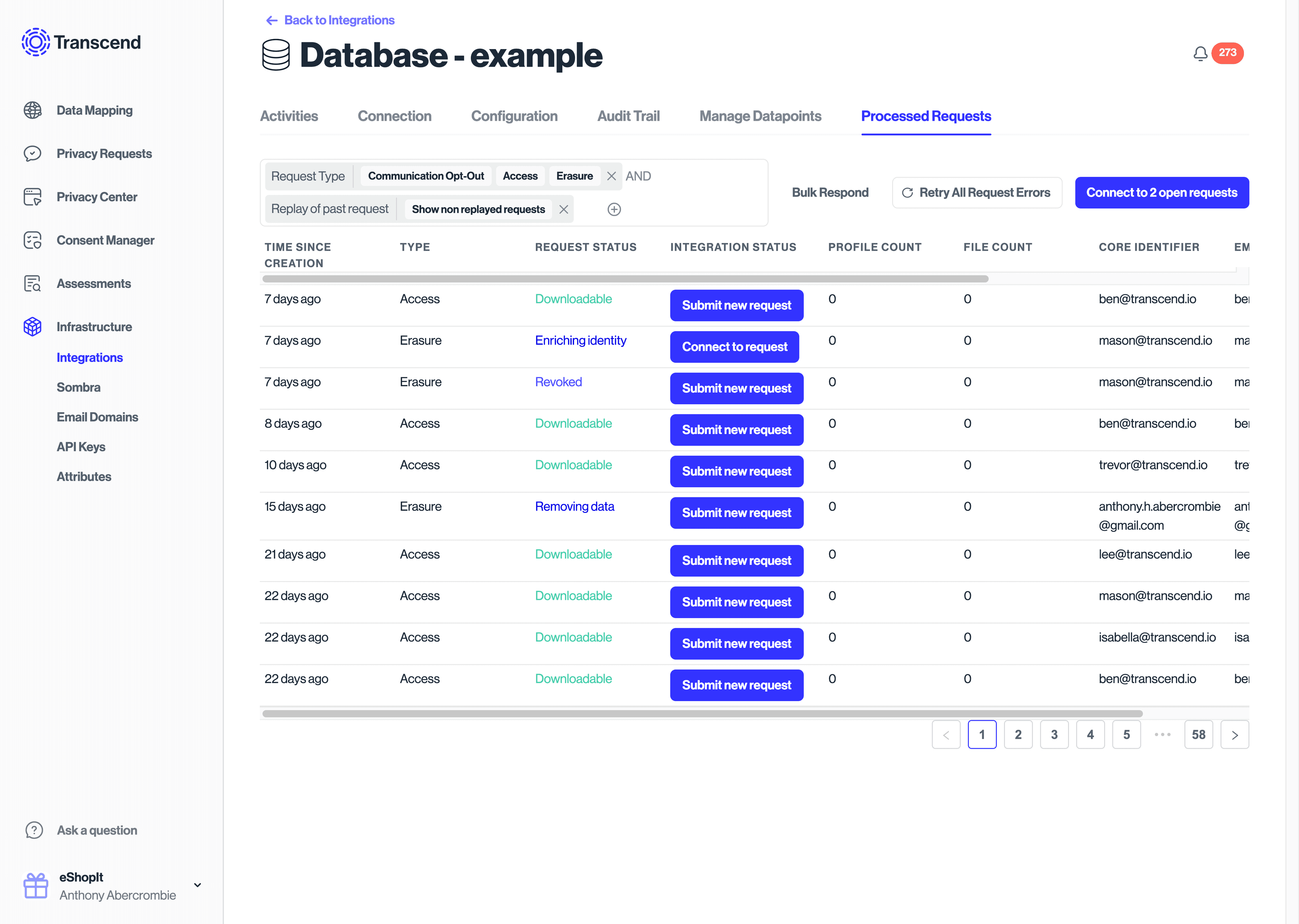
After a test request has been made, select your database in the Infrastructure / Integrations view and view Processed Requests to see a log of requests that interacted with your database. Selecting these will allow you to drill down on details pertaining to the the request. Requests can also be restarted from this view.