Data Classification for Databricks
Transcend's Classification automatically classifies the data discovered in your database. By leveraging machine learning techniques, we can categorize and recommend the processing purpose for each piece of data discovered. With Structured Discovery, Transcend helps you keep your Data Inventory up to date through inevitable database schema changes. Check out our full Classification guide for more information about how it works.
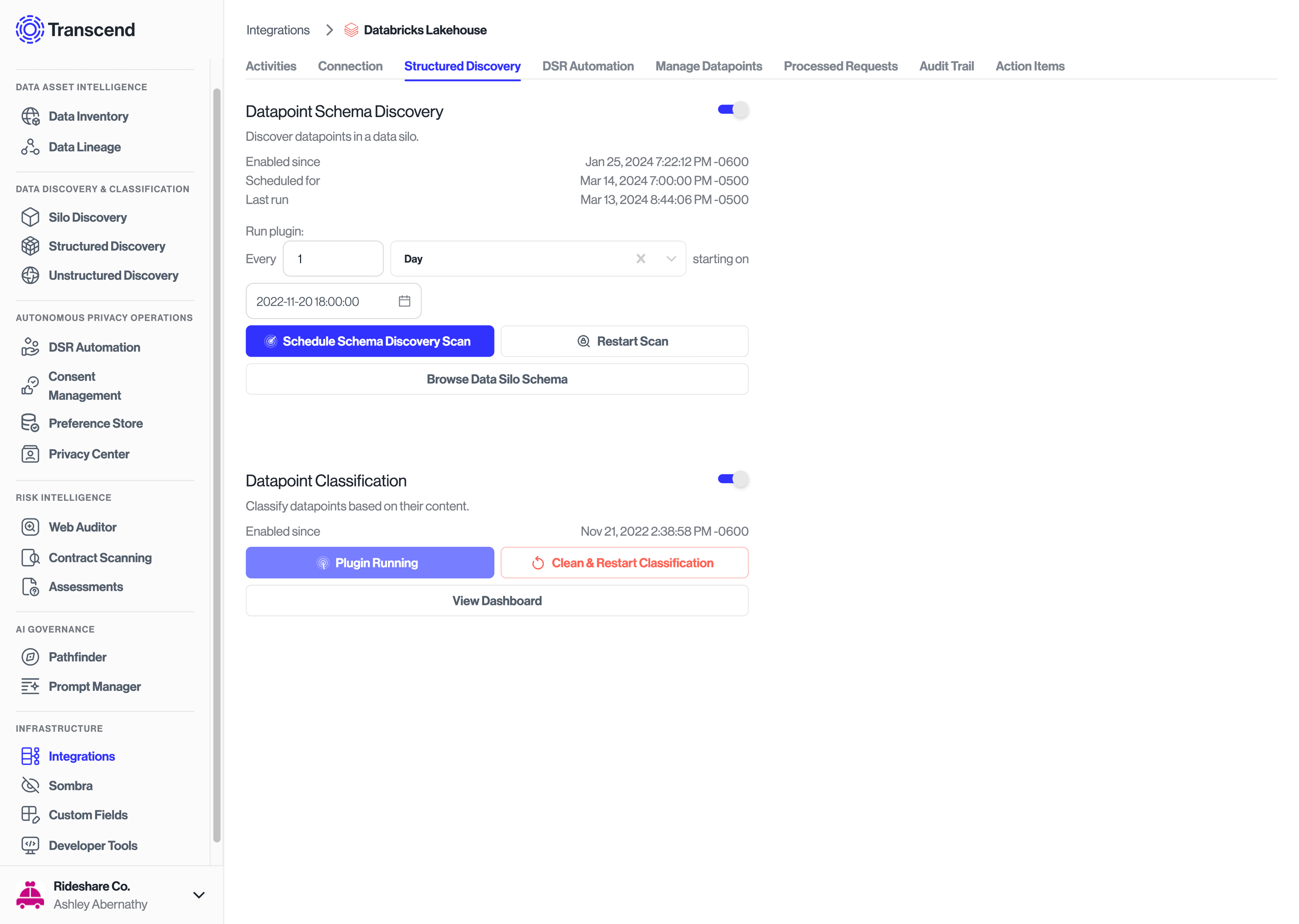
The Datapoint Schema Discovery plugin in the Databricks Lakehouse integration allows you to programmatically scan your database to identify the pieces of data in your DB and pull them into Transcend as objects and properties. Once the data is in Transcend, they can be classified, labeled, and configured for DSRs.
The plugin operates by sampling the database, generating an object within Transcend for each identified collection. Additionally, it discovers embedded arrays within these collections, each of which is also returned as an object, prefixed with the name of the parent collection for clarity. The plugin then delves deeper into the documents within each collection, and tracks every property it encounters, inclusive of nested properties. This comprehensive scanning process ensures a thorough mapping of your database structure within Transcend.
To enable the datapoint schema discovery plugin, navigate to the Structured Discovery tab within the Databricks Lakehouse data system and toggle the plugin on. From there, you'll be able to set the frequency for which the plugin will run to discover new objects and properties as they are added to the database. Note: We recommend scheduling the plugin to run at times when the load on the database is lightest.