Data Classification for MongoDB
Transcend's Classifcation tool automatically classifies the data discovered in your database. By leveraging machine learning techniques, we can categorize and recommend the processing purpose for each piece of data discovered. With Structured Discovery, Transcend helps you keep your Data Inventory up to date through inevitable database schema changes. Check out our full Classification guide for more information about how it works.
You can use the MongoDB integration to programmatically identify personal information in your MongoDB and pull it into Transcend as datapoint. Those datapoints are assigned a data category and processing purpose to help you classify internal data. Additionally, you can assign custom tags to your datapoints to allow for further classification, tracking and reporting. In this way, Transcend helps you discover, classify and label data in a MongoDB automatically to ensure your Data Inventory is current.
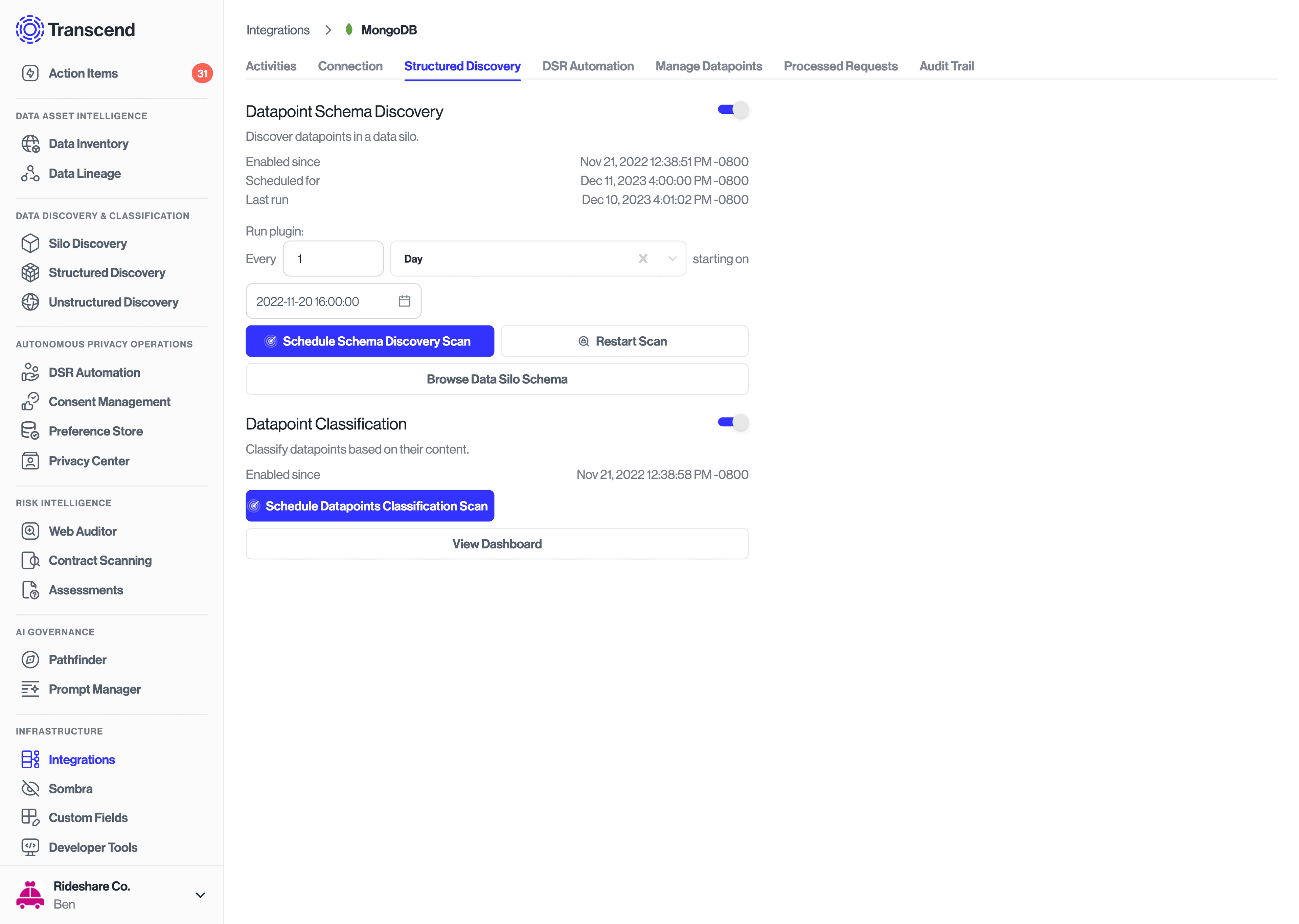
The Datapoint Schema Discovery plugin in the MongoDB integration allows you to programmatically scan your database to identify the pieces of data in your DB and pull them into Transcend as objects and properties. Once the data is in Transcend, they can be classified, labeled, and configured for DSRs.
The plugin operates by sampling the database and generating an object within Transcend for each identified collection. Sampling is done dynamically to handle larger collections, continuously halving the sample size and rerunning queries until successful which provides optimal performance even for extensive datasets. The plugin uses the $sample, $sort by _id, and $limit query to retrieve both the old and the newest documents and combine the results. Additionally, the plugin discovers embedded arrays within these collections, each of which is also returned as an object, prefixed with the name of the parent collection for clarity. This comprehensive scanning process ensures a thorough mapping of your database structure within Transcend.
Creating an object for each collection/embedded array creates an organization structure that mirrors the architecture of your data and keeps data grouped consistently. This makes it simple to keep track of the data hierarchy in Transcend, classify the data, and optionally implement DSRs against it.
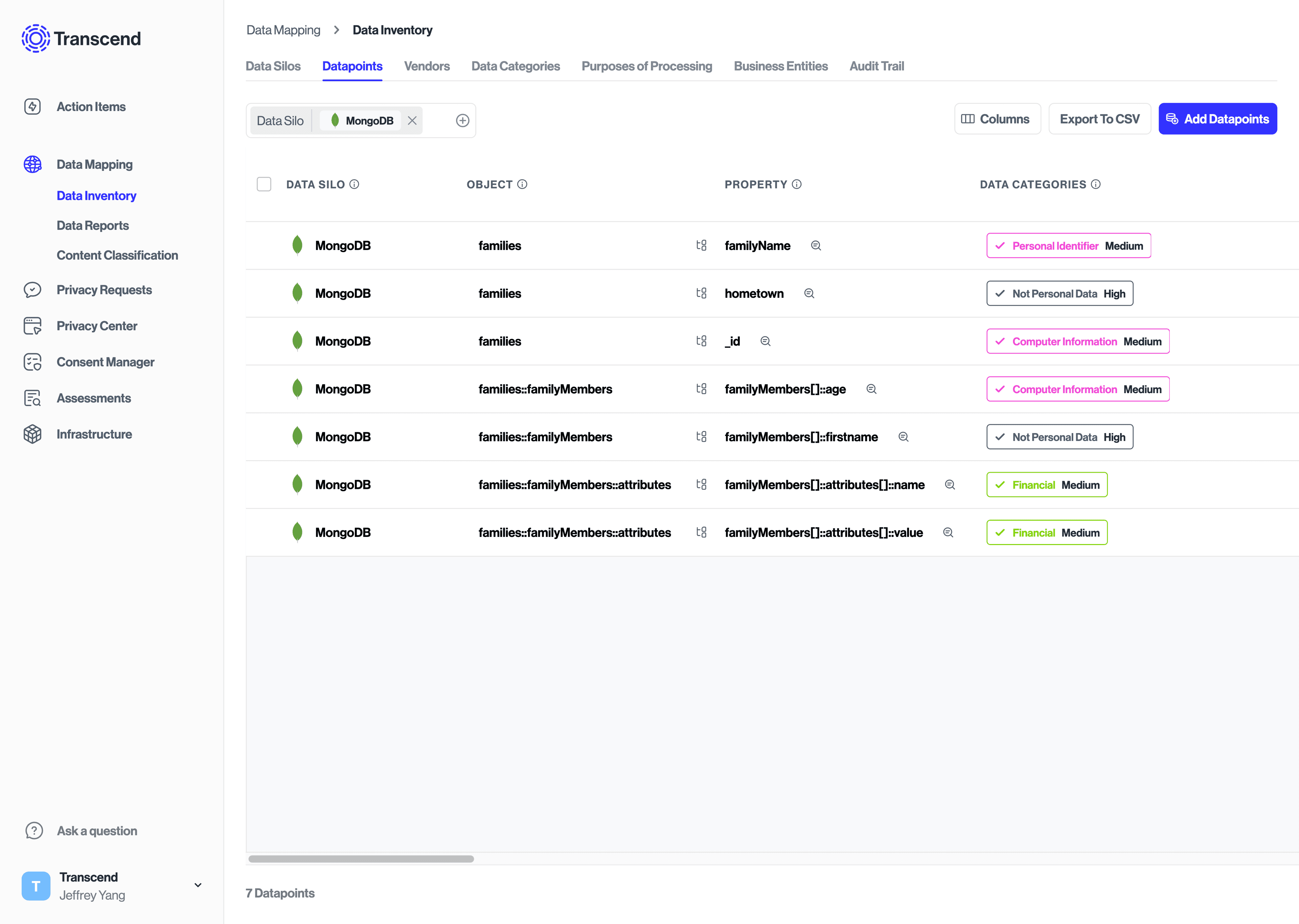
| Data System | Object | Property |
|---|---|---|
| MongoDB Database | Collections/Embedded Arrays | Properties |
The image below gives an example of schema discovery results with nested properties. For objects, each :: separates nested layers of array fields. For properties, we provide the full path to the field in MongoDB. The [] symbolizes an array field, and :: symbolizes an object field.
To enable the datapoint schema discovery plugin, navigate to the Structured Discovery tab within the MongoDB data system and toggle the plugin on. From there, you'll be able to set the frequency for which the plugin will run to discover new objects and properties as they are added to the database. Note: We recommend scheduling the plugin to run at times when the load on the database is lightest.