Databricks Integration Connection Guide
Transcend maintains an integration for Databricks and Databricks Lakehouse databases that supports Structured Discovery and DSR Automation functionality, allowing you to:
- Scan your database to identify datapoint that contain personal information
- Programmatically classify the data category and storage purpose of datapoints
- Define and execute DSRs directly against your database
The first step to connecting Databricks to Transcend is to add the Databricks integration through the Connect Integrations page.
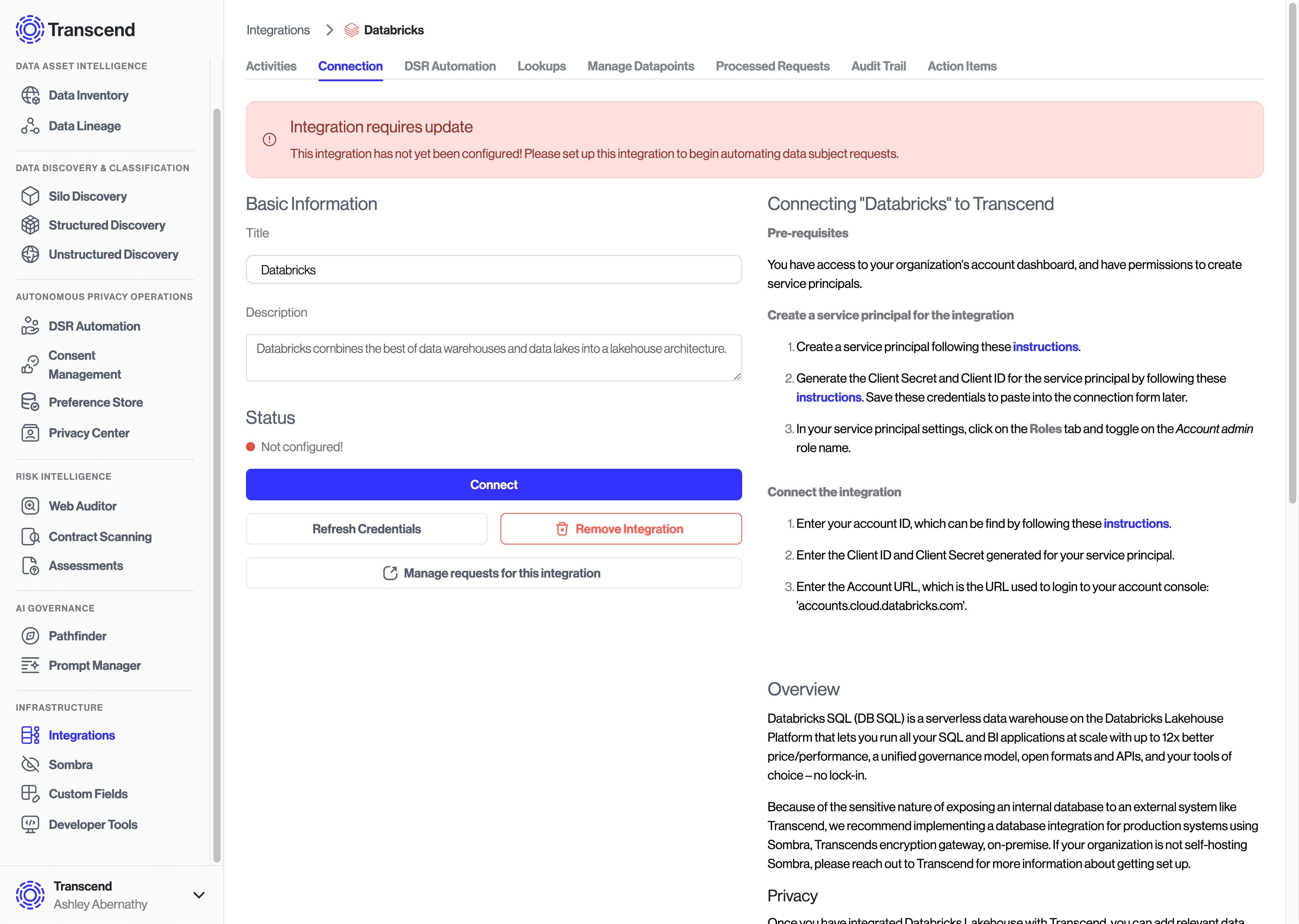
Create a service principle via these instructions and generate a Client ID and Secret. Be sure to add Account Admin role to the Service Principle.
Enter the Account ID, Account URL, Client Id and Client Secret string into the Integration Connection Form in Transcend and select Connect.
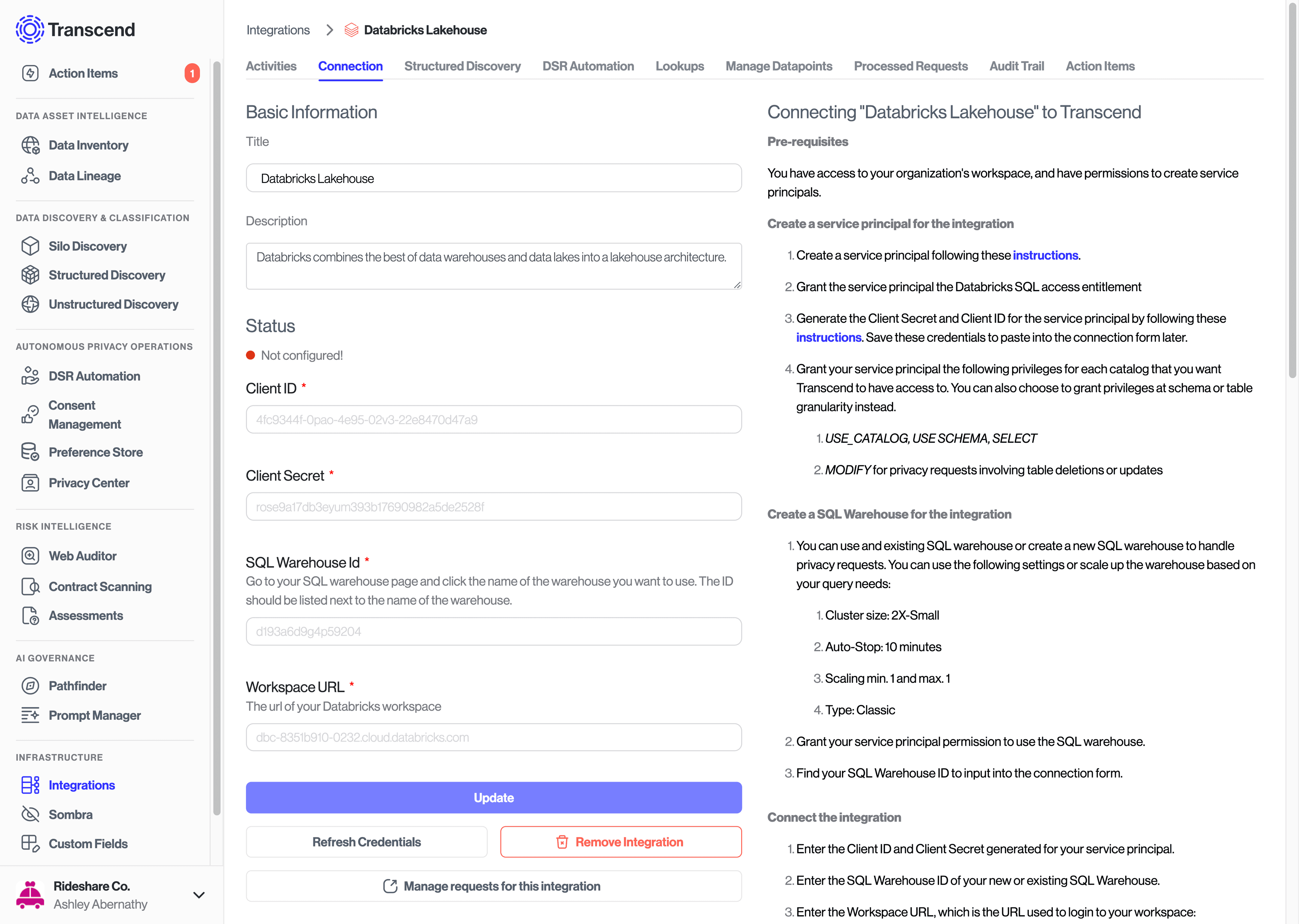
The first step to connecting Databricks Lakehouse to Transcend is to add the Databricks integration through the Connect Integrations page.
Create a service principle via these instructions and generate a Client ID and Secret. Be sure to add USE_CATALOG, USE SCHEMA, SELECT, and MODIFY privileges to the Service Principle for each catalog that you want Transcend to have access to.
Enter the SQL Warehouse ID, Warehouse URL, Client Id and Client Secret string into the Integration Connection Form in Transcend and select Connect.
After getting your Databricks integration connected, utilize the following guides to get the most out of your connection: